これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
クラスターの管理
- 1: dockershimからの移行
- 2: kubeadmによる管理
- 2.1: cgroupドライバーの設定
- 2.2: kubeadmによる証明書管理
- 2.3: Windowsノードの追加
- 2.4: Windowsノードのアップグレード
- 3: メモリー、CPU、APIリソースの管理
- 4: 証明書
- 5: EndpointSliceの有効化
- 6: KubernetesクラスターでNodeLocal DNSキャッシュを使用する
- 7: Serviceトポロジーを有効にする
- 8: サービスディスカバリーにCoreDNSを使用する
- 9: ノードのトポロジー管理ポリシーを制御する
- 10: クラウドコントローラーマネージャーの運用管理
- 11: クラウドコントローラーマネージャーの開発
- 12: クラスターのセキュリティ
- 13: ネットワークポリシーを宣言する
- 14: 拡張リソースをNodeにアドバタイズする
1 - dockershimからの移行
dockershimから他のコンテナランタイムに移行する際に知っておくべき情報を紹介します。
Kubernetes 1.20でdockershim deprecationが発表されてから、様々なワークロードやKubernetesインストールにどう影響するのかという質問が寄せられています。
この問題をよりよく理解するために、Dockershim Deprecation FAQブログが役に立つでしょう。
dockershimから代替のコンテナランタイムに移行することが推奨されます。 コンテナランタイムのセクションをチェックして、どのような選択肢があるかを確認してください。 問題が発生した場合は、必ず問題の報告をしてください。 そうすれば、問題が適時に修正され、クラスターがdockershimの削除に対応できるようになります。
1.1 - ノードで使用されているコンテナランタイムの確認
このページでは、クラスター内のノードが使用しているコンテナランタイムを確認する手順を概説しています。
クラスターの実行方法によっては、ノード用のコンテナランタイムが事前に設定されている場合と、設定する必要がある場合があります。
マネージドKubernetesサービスを使用している場合、ノードに設定されているコンテナランタイムを確認するためのベンダー固有の方法があるかもしれません。
このページで説明する方法は、kubectlの実行が許可されていればいつでも動作するはずです。
始める前に
kubectlをインストールし、設定します。詳細はツールのインストールの項を参照してください。
ノードで使用されているコンテナランタイムの確認
ノードの情報を取得して表示するにはkubectlを使用します:
kubectl get nodes -o wide
出力は以下のようなものです。列CONTAINER-RUNTIMEには、ランタイムとそのバージョンが出力されます。
# For dockershim
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.16.15 docker://19.3.1
node-2 Ready v1.16.15 docker://19.3.1
node-3 Ready v1.16.15 docker://19.3.1
# For containerd
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.19.6 containerd://1.4.1
node-2 Ready v1.19.6 containerd://1.4.1
node-3 Ready v1.19.6 containerd://1.4.1
コンテナランタイムについては、コンテナランタイムのページで詳細を確認することができます。
1.2 - Dockershim非推奨の影響範囲を確認する
Kubernetesのdockershimコンポーネントは、DockerをKubernetesのコンテナランタイムとして使用することを可能にします。
Kubernetesの組み込みコンポーネントであるdockershimはリリースv1.20で非推奨となりました。
このページでは、あなたのクラスターがどのようにDockerをコンテナランタイムとして使用しているか、使用中のdockershimが果たす役割について詳しく説明し、dockershimの廃止によって影響を受けるワークロードがあるかどうかをチェックするためのステップを示します。
自分のアプリがDockerに依存しているかどうかの確認
アプリケーションコンテナの構築にDockerを使用している場合でも、これらのコンテナを任意のコンテナランタイム上で実行することができます。このようなDockerの使用は、コンテナランタイムとしてのDockerへの依存とはみなされません。
代替のコンテナランタイムが使用されている場合、Dockerコマンドを実行しても動作しないか、予期せぬ出力が得られる可能性があります。
このように、Dockerへの依存があるかどうかを調べることができます:
- 特権を持つPodがDockerコマンド(
docker psなど)を実行したり、Dockerサービスを再起動したり(systemctl restart docker.serviceなどのコマンド)、Docker固有のファイル(/etc/docker/daemon.jsonなど)を変更しないことを確認すること。 - Dockerの設定ファイル(
/etc/docker/daemon.jsonなど)にプライベートレジストリやイメージミラーの設定がないか確認します。これらは通常、別のコンテナランタイムのために再設定する必要があります。 - Kubernetesインフラストラクチャーの外側のノードで実行される以下のようなスクリプトやアプリがDockerコマンドを実行しないことを確認します。
- トラブルシューティングのために人間がノードにSSHで接続
- ノードのスタートアップスクリプト
- ノードに直接インストールされた監視エージェントやセキュリティエージェント
- 上記のような特権的な操作を行うサードパーティツール。詳しくはMigrating telemetry and security agents from dockershim を参照してください。
- dockershimの動作に間接的な依存性がないことを確認します。 これはエッジケースであり、あなたのアプリケーションに影響を与える可能性は低いです。ツールによっては、Docker固有の動作に反応するように設定されている場合があります。例えば、特定のメトリクスでアラートを上げたり、トラブルシューティングの指示の一部として特定のログメッセージを検索したりします。そのようなツールを設定している場合、移行前にテストクラスターで動作をテストしてください。
Dockerへの依存について解説
コンテナランタイムとは、Kubernetes Podを構成するコンテナを実行できるソフトウェアです。
KubernetesはPodのオーケストレーションとスケジューリングを担当し、各ノードではkubeletがコンテナランタイムインターフェイスを抽象化して使用するので、互換性があればどのコンテナランタイムでも使用することができます。 初期のリリースでは、Kubernetesは1つのコンテナランタイムと互換性を提供していました: Dockerです。 その後、Kubernetesプロジェクトの歴史の中で、クラスター運用者は追加のコンテナランタイムを採用することを希望しました。 CRIはこのような柔軟性を可能にするために設計され、kubeletはCRIのサポートを開始しました。 しかし、DockerはCRI仕様が考案される前から存在していたため、Kubernetesプロジェクトはアダプタコンポーネント「dockershim」を作成しました。
dockershimアダプターは、DockerがCRI互換ランタイムであるかのように、kubeletがDockerと対話することを可能にします。 Kubernetes Containerd integration goes GAブログ記事で紹介されています。
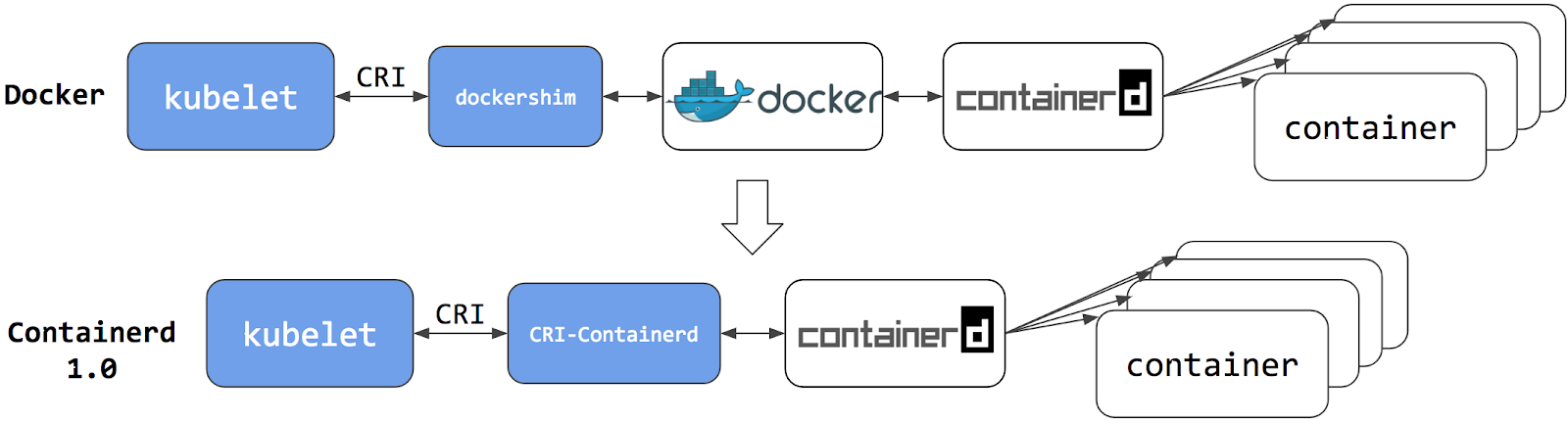
コンテナランタイムとしてContainerdに切り替えることで、中間マージンを排除することができます。
これまでと同じように、Containerdのようなコンテナランタイムですべてのコンテナを実行できます。
しかし今は、コンテナはコンテナランタイムで直接スケジュールするので、Dockerからは見えません。
そのため、これらのコンテナをチェックするために以前使っていたかもしれないDockerツールや派手なUIは、もはや利用できません。
docker psやdocker inspectを使用してコンテナ情報を取得することはできません。
コンテナを一覧表示できないので、ログを取得したり、コンテナを停止したり、docker execを使用してコンテナ内で何かを実行したりすることもできません。
この場合でも、イメージを取得したり、docker buildコマンドを使用してビルドすることは可能です。
しかし、Dockerによってビルドまたはプルされたイメージは、コンテナランタイムとKubernetesからは見えません。
Kubernetesで使用できるようにするには、何らかのレジストリにプッシュする必要がありました。
1.3 - dockershimからテレメトリーやセキュリティエージェントを移行する
Kubernetes 1.20でdockershimは非推奨になりました。
Dockershim Deprecation FAQから、ほとんどのアプリがコンテナをホストするランタイムに直接依存しないことは既にご存知かもしれません。 しかし、コンテナのメタデータやログ、メトリクスを収集するためにDockerに依存しているテレメトリーやセキュリティエージェントはまだ多く存在します。 この文書では、これらの依存関係を検出する方法と、これらのエージェントを汎用ツールまたは代替ランタイムに移行する方法に関するリンクを集約しています。
テレメトリーとセキュリティエージェント
Kubernetesクラスター上でエージェントを実行するには、いくつかの方法があります。エージェントはノード上で直接、またはDaemonSetとして実行することができます。
テレメトリーエージェントがDockerに依存する理由とは?
歴史的には、KubernetesはDockerの上に構築されていました。 Kubernetesはネットワークとスケジューリングを管理し、Dockerはコンテナをノードに配置して操作していました。 そのため、KubernetesからはPod名などのスケジューリング関連のメタデータを、Dockerからはコンテナの状態情報を取得することができます。 時が経つにつれ、コンテナを管理するためのランタイムも増えてきました。 また、多くのランタイムにまたがるコンテナ状態情報の抽出を一般化するプロジェクトやKubernetesの機能もあります。
いくつかのエージェントはDockerツールに関連しています。
エージェントはdocker psやdocker topといったコマンドを実行し、コンテナやプロセスの一覧を表示します。
またはdocker logsを使えば、dockerログを購読することができます。
Dockerがコンテナランタイムとして非推奨になったため、これらのコマンドはもう使えません。
Dockerに依存するDaemonSetの特定
Podがノード上で動作しているdockerdを呼び出したい場合、Podは以下のいずれかを行う必要があります。
-
Dockerデーモンの特権ソケットがあるファイルシステムをvolumeのようにマウントする。
-
Dockerデーモンの特権ソケットの特定のパスを直接ボリュームとしてマウントします。
例: COSイメージでは、DockerはそのUnixドメインソケットを/var/run/docker.sockに公開します。
つまり、Pod仕様には/var/run/docker.sockのhostPathボリュームマウントが含まれることになります。
以下は、Dockerソケットを直接マッピングしたマウントを持つPodを探すためのシェルスクリプトのサンプルです。
このスクリプトは、Podの名前空間と名前を出力します。
grep '/var/run/docker.sock'を削除して、他のマウントを確認することもできます。
kubectl get pods --all-namespaces \
-o=jsonpath='{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
| sort \
| grep '/var/run/docker.sock'
/var/runをマウントすることができます(この例 のように)。
上記のスクリプトは、最も一般的な使用方法のみを検出します。
ノードエージェントからDockerの依存性を検出する
クラスターノードをカスタマイズし、セキュリティやテレメトリーのエージェントをノードに追加インストールする場合、エージェントのベンダーにDockerへの依存性があるかどうかを必ず確認してください。
テレメトリーとセキュリティエージェントのベンダー
様々なテレメトリーおよびセキュリティエージェントベンダーのための移行指示の作業中バージョンをGoogle docに保管しています。 dockershimからの移行に関する最新の手順については、各ベンダーにお問い合わせください。
2 - kubeadmによる管理
2.1 - cgroupドライバーの設定
このページでは、kubeadmクラスターのコンテナランタイムcgroupドライバーに合わせて、kubelet cgroupドライバーを設定する方法について説明します。
始める前に
Kubernetesのコンテナランタイムの要件を熟知している必要があります。
コンテナランタイムのcgroupドライバーの設定
Container runtimesページでは、kubeadmベースのセットアップではcgroupfsドライバーではなく、systemdドライバーが推奨されると説明されています。
このページでは、デフォルトのsystemdドライバーを使用して多くの異なるコンテナランタイムをセットアップする方法についての詳細も説明されています。
kubelet cgroupドライバーの設定
kubeadmでは、kubeadm initの際にKubeletConfiguration構造体を渡すことができます。
このKubeletConfigurationには、kubeletのcgroupドライバーを制御するcgroupDriverフィールドを含めることができます。
KubeletConfigurationのcgroupDriverフィールドを設定していない場合、kubeadmはデフォルトでsystemdを設定するようになりました。
フィールドを明示的に設定する最小限の例です:
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
このような設定ファイルは、kubeadmコマンドに渡すことができます:
kubeadm init --config kubeadm-config.yaml
Kubeadmはクラスター内の全ノードで同じKubeletConfigurationを使用します。
KubeletConfigurationはkube-system名前空間下のConfigMapオブジェクトに格納されます。
サブコマンドinit、join、upgradeを実行すると、kubeadmがKubeletConfigurationを/var/lib/kubelet/config.yaml以下にファイルとして書き込み、ローカルノードのkubeletに渡します。
cgroupfsドライバーの使用
このガイドで説明するように、cgroupfsドライバーをkubeadmと一緒に使用することは推奨されません。
cgroupfsを使い続け、kubeadm upgradeが既存のセットアップでKubeletConfiguration cgroupドライバーを変更しないようにするには、その値を明示的に指定する必要があります。
これは、将来のバージョンのkubeadmにsystemdドライバーをデフォルトで適用させたくない場合に適用されます。
値を明示する方法については、後述の「kubelet ConfigMapの修正」の項を参照してください。
cgroupfsドライバーを使用するようにコンテナランタイムを設定したい場合は、選択したコンテナランタイムのドキュメントを参照する必要があります。
systemdドライバーへの移行
既存のkubeadmクラスターのcgroupドライバーをsystemdにインプレースで変更する場合は、kubeletのアップグレードと同様の手順が必要です。
これには、以下に示す両方の手順を含める必要があります。
systemdドライバーを使用する新しいノードに置き換えることも可能です。
この場合、新しいノードに参加する前に以下の最初のステップのみを実行し、古いノードを削除する前にワークロードが新しいノードに安全に移動できることを確認する必要があります。
kubelet ConfigMapの修正
kubectl get cm -n kube-system | grep kubelet-configで、kubelet ConfigMapの名前を探します。kubectl edit cm kubelet-config-x.yy -n kube-systemを呼び出します(x.yyはKubernetesのバージョンに置き換えてください)。- 既存の
cgroupDriverの値を修正するか、以下のような新しいフィールドを追加します。
``yaml cgroupDriver: systemd
このフィールドは、ConfigMapの`kubelet:`セクションの下に存在する必要があります。
### 全ノードでcgroupドライバーを更新
クラスター内の各ノードについて:
- [Drain the node](/docs/tasks/administer-cluster/safely-drain-node)を`kubectl drain <node-name> --ignore-daemonsets`を使ってドレーンします。
- `systemctl stop kubelet`を使用して、kubeletを停止します。
- コンテナランタイムの停止。
- コンテナランタイムのcgroupドライバーを`systemd`に変更します。
- `var/lib/kubelet/config.yaml`に`cgroupDriver: systemd`を設定します。
- コンテナランタイムの開始。
- `systemctl start kubelet`でkubeletを起動します。
- [Drain the node](/docs/tasks/administer-cluster/safely-drain-node)を`kubectl uncordon <node-name>`を使って行います。
ワークロードが異なるノードでスケジュールするための十分な時間を確保するために、これらのステップを1つずつノード上で実行します。
プロセスが完了したら、すべてのノードとワークロードが健全であることを確認します。
2.2 - kubeadmによる証明書管理
Kubernetes v1.15 [stable]
kubeadmで生成されたクライアント証明書は1年で失効します。 このページでは、kubeadmで証明書の更新を管理する方法について説明します。
始める前に
KubernetesにおけるPKI証明書と要件を熟知している必要があります。
カスタム証明書の使用
デフォルトでは、kubeadmはクラスターの実行に必要なすべての証明書を生成します。 独自の証明書を提供することで、この動作をオーバーライドできます。
そのためには、--cert-dirフラグまたはkubeadmのClusterConfigurationのcertificatesDirフィールドで指定された任意のディレクトリに配置する必要があります。
デフォルトは/etc/kubernetes/pkiです。
kubeadm init を実行する前に与えられた証明書と秘密鍵のペアが存在する場合、kubeadmはそれらを上書きしません。
つまり、例えば既存のCAを/etc/kubernetes/pki/ca.crtと/etc/kubernetes/pki/ca.keyにコピーすれば、kubeadmは残りの証明書に署名する際、このCAを使用できます。
外部CAモード
また、ca.crtファイルのみを提供し、ca.keyファイルを提供しないことも可能です(これはルートCAファイルのみに有効で、他の証明書ペアには有効ではありません)。
他の証明書とkubeconfigファイルがすべて揃っている場合、kubeadmはこの状態を認識し、外部CAモードを有効にします。
kubeadmはディスク上のCAキーがなくても処理を進めます。
代わりに、Controller-managerをスタンドアロンで、--controllers=csrsignerと実行し、CA証明書と鍵を指し示します。
PKI certificates and requirementsには、外部CAを使用するためのクラスターのセットアップに関するガイダンスが含まれています。
証明書の有効期限の確認
check-expirationサブコマンドを使うと、証明書の有効期限を確認することができます。
kubeadm certs check-expiration
このような出力になります:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
このコマンドは、/etc/kubernetes/pkiフォルダ内のクライアント証明書と、kubeadmが使用するKUBECONFIGファイル(admin.conf,controller-manager.conf,scheduler.conf)に埋め込まれたクライアント証明書の有効期限/残余時間を表示します。
また、証明書が外部管理されている場合、kubeadmはユーザーに通知します。この場合、ユーザーは証明書の更新を手動または他のツールを使用して管理する必要があります。
kubeadmは外部CAによって署名された証明書を管理することができません。
kubeadmは/var/lib/kubelet/pki以下にあるローテート可能な証明書でkubeletの証明書の自動更新を構成するのでkubelet.confは上記のリストに含まれません。
期限切れのkubeletクライアント証明書を修復するには、Kubelet クライアント証明書のローテーションに失敗しましたを参照ください。
kubeadm version 1.17より前のkubeadm initで作成したノードでは、kubelet.confの内容を手動で変更しなければならないというbugが存在します。
kubeadm initが終了したら、client-certificate-dataとclient-key-dataを置き換えて、ローテーションされたkubeletクライアント証明書を指すようにkubelet.confを更新してください。
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
証明書の自動更新
kubeadmはコントロールプレーンのアップグレード時にすべての証明書を更新します。
この機能は、最もシンプルなユースケースに対応するために設計されています。 証明書の更新に特別な要件がなく、Kubernetesのバージョンアップを定期的に行う場合(各アップグレードの間隔が1年未満)、kubeadmがクラスターを最新かつ適度に安全に保つための処理を行います。
証明書の更新に関してより複雑な要求がある場合は、--certificate-renewal=falseをkubeadm upgrade applyやkubeadm upgrade nodeに渡して、デフォルトの動作から外れるようにすることができます。
kubeadm upgrade nodeコマンドの--certificate-renewalのデフォルト値がfalseになっているという[bug(https://github.com/kubernetes/kubeadm/issues/1818)]問題があります。
この場合、明示的に--certificate-renewal=trueを設定する必要があります。
手動による証明書更新
kubeadm certs renew コマンドを使えば、いつでも証明書を手動で更新することができます。
このコマンドは/etc/kubernetes/pkiに格納されているCA(またはfront-proxy-CA)の証明書と鍵を使って更新を行います。
コマンド実行後、コントロールプレーンのPodを再起動する必要があります。 これは、現在すべてのコンポーネントと証明書について動的な証明書のリロードがサポートされていないため、必要な作業です。 スタティックPodはローカルkubeletによって管理され、API Serverによって管理されないため、kubectlで削除および再起動することはできません。
スタティックPodを再起動するには、一時的に/etc/kubernetes/manifests/からマニフェストファイルを削除して20秒間待ちます(KubeletConfiguration structのfileCheckFrequency値を参照してください)。
マニフェストディレクトリにPodが無くなると、kubeletはPodを終了します。
その後ファイルを戻して、さらにfileCheckFrequency期間後に、kubeletはPodを再作成し、コンポーネントの証明書更新を完了することができます。
certs renewは、属性(Common Name、Organization、SANなど)の信頼できるソースとして、kubeadm-config ConfigMapではなく、既存の証明書を使用します。両者を同期させておくことが強く推奨されます。
kubeadm certs renew は以下のオプションを提供します:
Kubernetesの証明書は通常1年後に有効期限を迎えます。
-
--csr-onlyを使用すると、証明書署名要求を生成して外部CAとの証明書を更新することができます(実際にはその場で証明書を更新しません)。詳しくは次の段落を参照してください。 -
また、すべての証明書を更新するのではなく、1つの証明書を更新することも可能です。
Kubernetes certificates APIによる証明書の更新
ここでは、Kubernetes certificates APIを使用して手動で証明書更新を実行する方法について詳しく説明します。
署名者の設定
Kubernetesの認証局は、そのままでは機能しません。 cert-managerなどの外部署名者を設定するか、組み込みの署名者を使用することができます。
ビルトインサイナーはkube-controller-managerに含まれるものです。
ビルトインサイナーを有効にするには、--cluster-signing-cert-fileと--cluster-signing-key-fileフラグを渡す必要があります。
新しいクラスターを作成する場合は、kubeadm設定ファイルを使用します。
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
controllerManager:
extraArgs:
cluster-signing-cert-file: /etc/kubernetes/pki/ca.crt
cluster-signing-key-file: /etc/kubernetes/pki/ca.key
証明書署名要求の作成 (CSR)
Kubernetes APIでのCSR作成については、Create CertificateSigningRequestを参照ください。
外部CAによる証明書の更新
ここでは、外部認証局を利用して手動で証明書更新を行う方法について詳しく説明します。
外部CAとの連携を強化するために、kubeadmは証明書署名要求(CSR)を生成することもできます。 CSRとは、クライアント用の署名付き証明書をCAに要求することを表します。 kubeadmの用語では、通常ディスク上のCAによって署名される証明書をCSRとして生成することができます。しかし、CAはCSRとして生成することはできません。
証明書署名要求の作成 (CSR)
kubeadm certs renew --csr-onlyで証明書署名要求を作成することができます。
CSRとそれに付随する秘密鍵の両方が出力されます。
ディレクトリを--csr-dirで渡すと、指定した場所にCSRを出力することができます。
csr-dirを指定しない場合は、デフォルトの証明書ディレクトリ(/etc/kubernetes/pki)が使用されます。
証明書はkubeadm certs renew --csr-onlyで更新することができます。
kubeadm initと同様に、--csr-dirフラグで出力先ディレクトリを指定することができます。
CSRには、証明書の名前、ドメイン、IPが含まれますが、用途は指定されません。 証明書を発行する際に、正しい証明書の使用法を指定するのはCAの責任です。
-
opensslでは、openssl caコマンドを使って行います。 -
cfsslでは、configファイルのusagesで指定します。
お好みの方法で証明書に署名した後、証明書と秘密鍵をPKIディレクトリ(デフォルトでは/etc/kubernetes/pki)にコピーする必要があります。
認証局(CA)のローテーション
Kubeadmは、CA証明書のローテーションや交換を最初からサポートしているわけではありません。
CAの手動ローテーションや交換についての詳細は、manual rotation of CA certificatesを参照してください。
署名付きkubeletサービング証明書の有効化
デフォルトでは、kubeadmによって展開されるkubeletサービング証明書は自己署名されています。
これは、metrics-serverのような外部サービスからキューブレットへの接続がTLSで保護されないことを意味します。
新しいkubeadmクラスター内のkubeletが適切に署名されたサービング証明書を取得するように設定するには、kubeadm initに以下の最小限の設定を渡す必要があります。
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
serverTLSBootstrap: true
すでにクラスターを作成している場合は、以下の手順で適応させる必要があります。
- kube-system
ネームスペースにあるkubelet-config-1.25` ConfigMapを見つけて編集します。
そのConfigMapのkubeletキーの値としてKubeletConfigurationドキュメントを指定します。KubeletConfigurationドキュメントを編集し、serverTLSBootstrap: trueを設定します。
- 各ノードで、
/var/lib/kubelet/config.yamlにserverTLSBootstrap: trueフィールドを追加し、systemctl restart kubeletでkubeletを再起動します。
serverTLSBootstrap: trueフィールドは、kubeleサービングのブートストラップを有効にします。
証明書をcertificates.k8s.ioAPIにリクエストすることで、証明書を発行することができます。
既知の制限事項として、これらの証明書のCSR(Certificate Signing Requests)はkube-controller-managerのデフォルトサイナーによって自動的に承認されないことがあります。
kubernetes.io/kubelet-serving を参照してください。
これには、ユーザーまたはサードパーティーのコントローラーからのアクションが必要です。
これらのCSRは、以下を使用して表示できます:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
承認するためには、次のようにします:
kubectl certificate approve <CSR-name>
デフォルトでは、これらのサービング証明書は1年後に失効します。
KubeadmはKubeletConfigurationフィールドrotateCertificatesをtrueに設定します。これは有効期限が切れる間際に、サービング証明書のための新しいCSRセットを作成し、ローテーションを完了するために承認する必要があることを意味します。
詳しくはCertificate Rotationをご覧ください。
これらのCSRを自動的に承認するためのソリューションをお探しの場合は、以下をお勧めします。 クラウドプロバイダーに連絡し、ノードの識別をアウトオブバンドのメカニズムで行うCSRの署名者がいるかどうか尋ねてください。
サードパーティーのカスタムコントローラーを使用することができます。
このようなコントローラーは、CSRのCommonNameを検証するだけでなく、要求されたIPやドメイン名も検証しなければ、安全なメカニズムとは言えません。これにより、kubeletクライアント証明書にアクセスできる悪意のあるアクターが、任意のIPやドメイン名に対してサービング証明書を要求するCSRを作成することを防ぐことができます。
2.3 - Windowsノードの追加
Kubernetes v1.18 [beta]
Kubernetesを使用してLinuxノードとWindowsノードを混在させて実行できるため、Linuxで実行するPodとWindowsで実行するPodを混在させることができます。このページでは、Windowsノードをクラスターに登録する方法を示します。
始める前に
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.17. バージョンを確認するには次のコマンドを実行してください:kubectl version.
-
WindowsコンテナをホストするWindowsノードを構成するには、Windows Server 2019ライセンス(またはそれ以上)を取得します。 VXLAN/オーバーレイネットワークを使用している場合は、KB4489899もインストールされている必要があります。
-
コントロールプレーンにアクセスできるLinuxベースのKubernetes kubeadmクラスター(kubeadmを使用したシングルコントロールプレーンクラスターの作成を参照)
目標
- Windowsノードをクラスターに登録する
- LinuxとWindowsのPodとServiceが相互に通信できるようにネットワークを構成する
はじめに: クラスターへのWindowsノードの追加
ネットワーク構成
LinuxベースのKubernetesコントロールプレーンノードを取得したら、ネットワーキングソリューションを選択できます。このガイドでは、簡単にするためにVXLANモードでのFlannelの使用について説明します。
Flannel構成
-
FlannelのためにKubernetesコントロールプレーンを準備する
クラスター内のKubernetesコントロールプレーンでは、多少の準備が推奨されます。Flannelを使用する場合は、iptablesチェーンへのブリッジIPv4トラフィックを有効にすることをお勧めします。すべてのLinuxノードで次のコマンドを実行する必要があります:
sudo sysctl net.bridge.bridge-nf-call-iptables=1 -
Linux用のFlannelをダウンロードして構成する
最新のFlannelマニフェストをダウンロード:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlVNIを4096、ポートを4789に設定するために、flannelマニフェストの
net-conf.jsonセクションを変更します。次のようになります:net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan", "VNI" : 4096, "Port": 4789 } }備考: Linux上のFlannelがWindows上のFlannelと相互運用するには、VNIを4096およびポート4789に設定する必要があります。これらのフィールドの説明については、VXLANドキュメントを参照してください。備考: L2Bridge/Host-gatewayモードを使用するには、代わりにTypeの値を"host-gw"に変更し、VNIとPortを省略します。 -
Flannelマニフェストを適用して検証する
Flannelの構成を適用しましょう:
kubectl apply -f kube-flannel.yml数分後、Flannel Podネットワークがデプロイされていれば、すべてのPodが実行されていることがわかります。
kubectl get pods -n kube-system出力結果には、実行中のLinux flannel DaemonSetが含まれているはずです:
NAMESPACE NAME READY STATUS RESTARTS AGE ... kube-system kube-flannel-ds-54954 1/1 Running 0 1m -
Windows Flannelとkube-proxy DaemonSetを追加する
これで、Windows互換バージョンのFlannelおよびkube-proxyを追加できます。 互換性のあるバージョンのkube-proxyを確実に入手するには、イメージのタグを置換する必要があります。 次の例は、Kubernetesv1.25.0の使用方法を示していますが、 独自のデプロイに合わせてバージョンを調整する必要があります。
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.25.0/g' | kubectl apply -f - kubectl apply -f https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml備考: ホストゲートウェイを使用している場合は、代わりに https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-host-gw.yml を使用してください。備考:Windowsノードでイーサネット(「Ethernet0 2」など)ではなく別のインターフェースを使用している場合は、次の行を変更する必要があります:
wins cli process run --path /k/flannel/setup.exe --args "--mode=overlay --interface=Ethernet"flannel-host-gw.ymlまたはflannel-overlay.ymlファイルで、それに応じてインターフェースを指定します。# 例 curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml | sed 's/Ethernet/Ethernet0 2/g' | kubectl apply -f -
Windowsワーカーノードの参加
Containers機能をインストールし、Dockerをインストールする必要があります。
行うための指示としては、Dockerエンジンのインストール - Windowsサーバー上のエンタープライズを利用できます。
-
wins、kubelet、kubeadmをインストールします。
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/kubeadm/scripts/PrepareNode.ps1 .\PrepareNode.ps1 -KubernetesVersion -
kubeadmを実行してノードに参加しますコントロールプレーンホストで
kubeadm initを実行したときに提供されたコマンドを使用します。 このコマンドがなくなった場合、またはトークンの有効期限が切れている場合は、kubeadm token create --print-join-command(コントロールプレーンホスト上で)を実行して新しいトークンを生成します。
インストールの確認
次のコマンドを実行して、クラスター内のWindowsノードを表示できるようになります:
kubectl get nodes -o wide
新しいノードがNotReady状態の場合は、flannelイメージがまだダウンロード中の可能性があります。
kube-system名前空間のflannel Podを確認することで、以前と同様に進行状況を確認できます:
kubectl -n kube-system get pods -l app=flannel
flannel Podが実行されると、ノードはReady状態になり、ワークロードを処理できるようになります。
次の項目
2.4 - Windowsノードのアップグレード
Kubernetes v1.18 [beta]
このページでは、kubeadmで作られたWindowsノードをアップグレードする方法について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.17. バージョンを確認するには次のコマンドを実行してください:kubectl version.
- 残りのkubeadmクラスターをアップグレードするプロセスを理解します。 Windowsノードをアップグレードする前にコントロールプレーンノードをアップグレードしたいと思うかもしれません。
ワーカーノードをアップグレード
kubeadmをアップグレード
-
Windowsノードから、kubeadmをアップグレードします。:
# v1.25.0を目的のバージョンに置き換えます curl.exe -Lo C:\k\kubeadm.exe https://dl.k8s.io//bin/windows/amd64/kubeadm.exe
ノードをドレインする
-
Kubernetes APIにアクセスできるマシンから、 ノードをスケジュール不可としてマークして、ワークロードを削除することでノードのメンテナンスを準備します:
# <node-to-drain>をドレインするノードの名前に置き換えます kubectl drain <node-to-drain> --ignore-daemonsetsこのような出力結果が表示されるはずです:
node/ip-172-31-85-18 cordoned node/ip-172-31-85-18 drained
kubeletの構成をアップグレード
-
Windowsノードから、次のコマンドを呼び出して新しいkubelet構成を同期します:
kubeadm upgrade node
kubeletをアップグレード
-
Windowsノードから、kubeletをアップグレードして再起動します:
stop-service kubelet curl.exe -Lo C:\k\kubelet.exe https://dl.k8s.io//bin/windows/amd64/kubelet.exe restart-service kubelet
ノードをオンライン状態に
-
Kubernetes APIにアクセスできるマシンから、 スケジュール可能としてマークして、ノードをオンラインに戻します:
# <node-to-drain>をノードの名前に置き換えます kubectl uncordon <node-to-drain>
kube-proxyをアップグレード
-
Kubernetes APIにアクセスできるマシンから、次を実行します、 もう一度v1.25.0を目的のバージョンに置き換えます:
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.25.0/g' | kubectl apply -f -
3 - メモリー、CPU、APIリソースの管理
3.1 - ネームスペースのデフォルトのメモリー要求と制限を設定する
このページでは、ネームスペースのデフォルトのメモリー要求と制限を設定する方法を説明します。
Kubernetesクラスターはネームスペースに分割することができます。デフォルトのメモリー制限を持つネームスペースがあり、独自のメモリー制限を指定しないコンテナでPodを作成しようとすると、コントロールプレーンはそのコンテナにデフォルトのメモリー制限を割り当てます。
Kubernetesは、このトピックで後ほど説明する特定の条件下で、デフォルトのメモリー要求を割り当てます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
クラスターにネームスペースを作成するには、アクセス権が必要です。
クラスターの各ノードには、最低でも2GiBのメモリーが必要です。
ネームスペースの作成
この演習で作成したリソースがクラスターの他の部分から分離されるように、ネームスペースを作成します。
kubectl create namespace default-mem-example
LimitRangeとPodの作成
以下は、LimitRangeのマニフェストの例です。このマニフェストでは、デフォルトのメモリー要求とデフォルトのメモリー制限を指定しています。

apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
default-mem-exampleネームスペースにLimitRangeを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace=default-mem-example
default-mem-exampleネームスペースでPodを作成し、そのPod内のコンテナがメモリー要求とメモリー制限の値を独自に指定しない場合、コントロールプレーンはデフォルト値のメモリー要求256MiBとメモリー制限512MiBを適用します。
以下は、コンテナを1つ持つPodのマニフェストの例です。コンテナは、メモリー要求とメモリー制限を指定していません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo
spec:
containers:
- name: default-mem-demo-ctr
image: nginx
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo --output=yaml --namespace=default-mem-example
この出力は、Podのコンテナのメモリー要求が256MiBで、メモリー制限が512MiBであることを示しています。 これらはLimitRangeで指定されたデフォルト値です。
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
Podを削除します:
kubectl delete pod default-mem-demo --namespace=default-mem-example
コンテナの制限を指定し、要求を指定しない場合
以下は1つのコンテナを持つPodのマニフェストです。コンテナはメモリー制限を指定しますが、メモリー要求は指定しません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-2
spec:
containers:
- name: default-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1Gi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
この出力は、コンテナのメモリー要求がそのメモリー制限に一致するように設定されていることを示しています。 コンテナにはデフォルトのメモリー要求値である256Miが割り当てられていないことに注意してください。
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
コンテナの要求を指定し、制限を指定しない場合
1つのコンテナを持つPodのマニフェストです。コンテナはメモリー要求を指定しますが、メモリー制限は指定しません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-3
spec:
containers:
- name: default-mem-demo-3-ctr
image: nginx
resources:
requests:
memory: "128Mi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
この出力は、コンテナのメモリー要求が、コンテナのマニフェストで指定された値に設定されていることを示しています。 コンテナは512MiB以下のメモリーを使用するように制限されていて、これはネームスペースのデフォルトのメモリー制限と一致します。
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
デフォルトのメモリー制限と要求の動機
ネームスペースにメモリーリソースクォータが設定されている場合、メモリー制限のデフォルト値を設定しておくと便利です。
以下はリソースクォータがネームスペースに課す制限のうちの2つです。
- ネームスペースで実行されるすべてのPodについて、Podとその各コンテナにメモリー制限を設ける必要があります(Pod内のすべてのコンテナに対してメモリー制限を指定すると、Kubernetesはそのコンテナの制限を合計することでPodレベルのメモリー制限を推測することができます)。
- メモリー制限は、当該Podがスケジュールされているノードのリソース予約を適用します。ネームスペース内のすべてのPodに対して予約されるメモリーの総量は、指定された制限を超えてはなりません。
- また、ネームスペース内のすべてのPodが実際に使用するメモリーの総量も、指定された制限を超えてはなりません。
LimitRangeの追加時:
コンテナを含む、そのネームスペース内のいずれかのPodが独自のメモリー制限を指定していない場合、コントロールプレーンはそのコンテナにデフォルトのメモリー制限を適用し、メモリーのResourceQuotaによって制限されているネームスペース内でPodを実行できるようにします。
クリーンアップ
ネームスペースを削除します:
kubectl delete namespace default-mem-example
次の項目
クラスター管理者向け
アプリケーション開発者向け
3.2 - Namespaceに対する最小および最大メモリー制約の構成
このページでは、Namespaceで実行されるコンテナが使用するメモリーの最小値と最大値を設定する方法を説明します。 LimitRange で最小値と最大値のメモリー値を指定します。 PodがLimitRangeによって課される制約を満たさない場合、そのNamespaceではPodを作成できません。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.
クラスター内の各ノードには、少なくとも1GiBのメモリーが必要です。
Namespaceの作成
この演習で作成したリソースがクラスターの他の部分から分離されるように、Namespaceを作成します。
kubectl create namespace constraints-mem-example
LimitRangeとPodを作成
LimitRangeの設定ファイルです。
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
LimitRangeを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
LimitRangeの詳細情報を表示します。
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
出力されるのは、予想通りメモリー制約の最小値と最大値を示しています。 しかし、LimitRangeの設定ファイルでデフォルト値を指定していないにもかかわらず、 自動的に作成されていることに気づきます。
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
constraints-mem-exampleNamespaceにコンテナが作成されるたびに、 Kubernetesは以下の手順を実行するようになっています。
-
コンテナが独自のメモリー要求と制限を指定しない場合は、デフォルトのメモリー要求と制限をコンテナに割り当てます。
-
コンテナに500MiB以上のメモリー要求があることを確認します。
-
コンテナのメモリー制限が1GiB以下であることを確認します。
以下は、1つのコンテナを持つPodの設定ファイルです。設定ファイルのコンテナ(containers)では、600MiBのメモリー要求と800MiBのメモリー制限が指定されています。これらはLimitRangeによって課される最小と最大のメモリー制約を満たしています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
Podの作成
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
Podのコンテナが実行されていることを確認します。
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
出力は、コンテナが600MiBのメモリ要求と800MiBのメモリー制限になっていることを示しています。これらはLimitRangeによって課される制約を満たしています。
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
Podを消します。
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
最大メモリ制約を超えるPodの作成の試み
これは、1つのコンテナを持つPodの設定ファイルです。コンテナは800MiBのメモリー要求と1.5GiBのメモリー制限を指定しています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
出力は、コンテナが大きすぎるメモリー制限を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
最低限のメモリ要求を満たさないPodの作成の試み
これは、1つのコンテナを持つPodの設定ファイルです。コンテナは100MiBのメモリー要求と800MiBのメモリー制限を指定しています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
出力は、コンテナが小さすぎるメモリー要求を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
メモリ要求や制限を指定しないPodの作成
これは、1つのコンテナを持つPodの設定ファイルです。コンテナはメモリー要求を指定しておらず、メモリー制限も指定していません。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
Podを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
出力を見ると、Podのコンテナのメモリ要求は1GiB、メモリー制限は1GiBであることがわかります。 コンテナはどのようにしてこれらの値を取得したのでしょうか?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeから与えられのです。 コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeからデフォルトのメモリー要求と制限が与えられたのです。
この時点で、コンテナは起動しているかもしれませんし、起動していないかもしれません。このタスクの前提条件は、ノードが少なくとも1GiBのメモリーを持っていることであることを思い出してください。それぞれのノードが1GiBのメモリーしか持っていない場合、どのノードにも1GiBのメモリー要求に対応するのに十分な割り当て可能なメモリーがありません。たまたま2GiBのメモリーを持つノードを使用しているのであれば、おそらく1GiBのメモリーリクエストに対応するのに十分なスペースを持っていることになります。
Podを削除します。
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
最小および最大メモリー制約の強制
LimitRangeによってNamespaceに課される最大および最小のメモリー制約は、Podが作成または更新されたときにのみ適用されます。LimitRangeを変更しても、以前に作成されたPodには影響しません。
最小・最大メモリー制約の動機
クラスター管理者としては、Podが使用できるメモリー量に制限を課したいと思うかもしれません。
例:
-
クラスター内の各ノードは2GBのメモリーを持っています。クラスタ内のどのノードもその要求をサポートできないため、2GB以上のメモリーを要求するPodは受け入れたくありません。
-
クラスターは運用部門と開発部門で共有されています。 本番用のワークロードでは最大8GBのメモリーを消費しますが、開発用のワークロードでは512MBに制限したいとします。本番用と開発用に別々のNamespaceを作成し、それぞれのNamespaceにメモリー制限を適用します。
クリーンアップ
Namespaceを削除します。
kubectl delete namespace constraints-mem-example
次の項目
クラスター管理者向け
アプリケーション開発者向け
4 - 証明書
クライアント証明書認証を使用する場合、easyrsa,opensslまたはcfsslを使って手動で証明書を生成することができます。
easyrsa
easyrsaはクラスターの証明書を手動で生成することができます。
-
パッチが適用されたバージョンのeasyrsa3をダウンロードし、解凍し、初期化します。
curl -LO https://storage.googleapis.com/kubernetes-release/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master/easyrsa3 ./easyrsa init-pki -
新しい認証局(CA)を生成します。
req-cnはCAの新しいルート証明書のコモンネーム(CN)を指定します。./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass -
サーバー証明書と鍵を生成します。 引数
--subject-alt-nameは、APIサーバーがアクセス可能なIPとDNS名を設定します。MASTER_CLUSTER_IPは通常、APIサーバーとコントローラーマネージャーコンポーネントの両方で--service-cluster-ip-range引数に指定したサービスCIDRの最初のIPとなります。 引数--daysは、証明書の有効期限が切れるまでの日数を設定するために使用します。 また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。./easyrsa --subject-alt-name="IP:${MASTER_IP},"\ "IP:${MASTER_CLUSTER_IP},"\ "DNS:kubernetes,"\ "DNS:kubernetes.default,"\ "DNS:kubernetes.default.svc,"\ "DNS:kubernetes.default.svc.cluster,"\ "DNS:kubernetes.default.svc.cluster.local" \ --days=10000 \ build-server-full server nopass -
pki/ca.crt,pki/issued/server.crt,pki/private/server.keyを自分のディレクトリにコピーします。 -
APIサーバーのスタートパラメーターに以下のパラメーターを記入し、追加します。
--client-ca-file=/yourdirectory/ca.crt --tls-cert-file=/yourdirectory/server.crt --tls-private-key-file=/yourdirectory/server.key
openssl
opensslは、クラスター用の証明書を手動で生成することができます。
-
2048bitのca.keyを生成します:
openssl genrsa -out ca.key 2048 -
ca.keyに従ってca.crtを生成します(-daysで証明書の有効期限を設定します)。
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt -
2048bitでserver.keyを生成します:
openssl genrsa -out server.key 2048 -
証明書署名要求(CSR)を生成するための設定ファイルを作成します。 角括弧で囲まれた値(例:
<MASTER_IP>)は必ず実際の値に置き換えてから、ファイル(例:csr.conf)に保存してください。MASTER_CLUSTER_IPの値は、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPであることに注意してください。また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <country> ST = <state> L = <city> O = <organization> OU = <organization unit> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_names -
設定ファイルに基づき、証明書署名要求を生成します:
openssl req -new -key server.key -out server.csr -config csr.conf -
ca.key、ca.crt、server.csrを使用して、サーバー証明書を生成します:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -
証明書署名要求を表示します:
openssl req -noout -text -in ./server.csr -
証明書を表示します:
openssl x509 -noout -text -in ./server.crt
最後に、同じパラメーターをAPIサーバーのスタートパラメーターに追加します。
cfssl
cfsslも証明書生を成するためのツールです。
-
以下のように、コマンドラインツールをダウンロードし、解凍して準備してください。 なお、サンプルのコマンドは、お使いのハードウェア・アーキテクチャやCFSSLのバージョンに合わせる必要があるかもしれません。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl chmod +x cfssl curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson chmod +x cfssljson curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo chmod +x cfssl-certinfo -
成果物を格納するディレクトリを作成し、cfsslを初期化します:
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.json -
CAファイルを生成するためのJSON設定ファイル、例えば
ca-config.jsonを作成します:{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } -
CA証明書署名要求(CSR)用のJSON設定ファイル(例:
ca-csr.json)を作成します。 角括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
CAキー(
ca-key.pem)と証明書(ca.pem)を生成します:../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca -
APIサーバーの鍵と証明書を生成するためのJSON設定ファイル、例えば
server-csr.jsonを作成します。 角括弧内の値は、必ず使用したい実際の値に置き換えてください。MASTER_CLUSTER_IPは、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPです。 また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
APIサーバーの鍵と証明書を生成します。 デフォルトでは、それぞれ
server-key.pemとserver.pemというファイルに保存されます:../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
自己署名入りCA証明書を配布する
クライアントノードが自己署名入りCA証明書を有効なものとして認識できない場合があります。
非プロダクション環境、または会社のファイアウォールの内側での開発環境であれば、自己署名入りCA証明書をすべてのクライアントに配布し、有効な証明書のローカルリストを更新することができます。
各クライアントで、次の操作を実行します:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
証明書API
認証に使用するx509証明書のプロビジョニングにはcertificates.k8s.io APIを使用することができます。ここに記述されています。
5 - EndpointSliceの有効化
このページはKubernetesのEndpointSliceの有効化の概要を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.
概要
EndpointSliceは、KubernetesのEndpointsに対してスケーラブルで拡張可能な代替手段を提供します。Endpointsが提供する機能のベースの上に構築し、スケーラブルな方法で拡張します。Serviceが多数(100以上)のネットワークエンドポイントを持つ場合、それらは単一の大きなEndpointsリソースではなく、複数の小さなEndpointSliceに分割されます。
EndpointSliceの有効化
Kubernetes v1.17 [beta]
EndpoitSliceはベータ版の機能です。APIとEndpointSliceコントローラーはデフォルトで有効です。kube-proxyはデフォルトでEndpointSliceではなくEndpointsを使用します。
スケーラビリティと性能向上のため、kube-proxy上でEndpointSliceProxyingフィーチャーゲートを有効にできます。この変更はデータソースをEndpointSliceに移します、これはkube-proxyとKubernetes API間のトラフィックの量を削減します。
EndpointSliceの使用
クラスター内でEndpointSliceを完全に有効にすると、各Endpointsリソースに対応するEndpointSliceリソースが表示されます。既存のEndpointsの機能をサポートすることに加えて、EndpointSliceはトポロジーなどの新しい情報を含みます。これらにより、クラスター内のネットワークエンドポイントのスケーラビリティと拡張性が大きく向上します。
次の項目
- EndpointSliceを参照してください。
- サービスとアプリケーションの接続を参照してください。
6 - KubernetesクラスターでNodeLocal DNSキャッシュを使用する
Kubernetes v1.18 [stable]
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.
イントロダクション
NodeLocal DNSキャッシュは、クラスターノード上でDNSキャッシュエージェントをDaemonSetで稼働させることで、クラスターのDNSパフォーマンスを向上させます。現在のアーキテクチャーにおいて、ClusterFirstのDNSモードでのPodは、DNSクエリー用にkube-dnsのService IPに疎通します。これにより、kube-proxyによって追加されたiptablesを介してkube-dns/CoreDNSのエンドポイントへ変換されます。この新しいアーキテクチャーによって、Podは同じノード上で稼働するDNSキャッシュエージェントに対して疎通し、それによってiptablesのDNATルールとコネクショントラッキングを回避します。ローカルのキャッシュエージェントはクラスターのホスト名(デフォルトではcluster.localというサフィックス)に対するキャッシュミスがあるときはkube-dnsサービスへ問い合わせます。
動機
-
現在のDNSアーキテクチャーでは、ローカルのkube-dns/CoreDNSがないとき、DNSへの秒間クエリー数が最も高いPodは他のノードへ疎通する可能性があります。ローカルでキャッシュを持つことにより、この状況におけるレイテンシーの改善に役立ちます。
-
iptables DNATとコネクショントラッキングをスキップすることはconntrackの競合を減らし、UDPでのDNSエントリーがconntrackテーブルを満杯にすることを避けるのに役立ちます。
-
ローカルのキャッシュエージェントからkube-dnsサービスへの接続がTCPにアップグレードされます。タイムアウトをしなくてはならないUDPエントリーと比べ、TCPのconntrackエントリーはコネクションクローズ時に削除されます(デフォルトの
nf_conntrack_udp_timeoutは30秒です)。 -
DNSクエリーをUDPからTCPにアップグレードすることで、UDPパケットの欠損や、通常30秒(10秒のタイムアウトで3回再試行する)であるDNSのタイムアウトによるテイルレイテンシーを減少させます。NodeLocalキャッシュはUDPのDNSクエリーを待ち受けるため、アプリケーションを変更する必要はありません。
-
DNSクエリーに対するノードレベルのメトリクスと可視性を得られます。
-
DNSの不在応答のキャッシュも再度有効にされ、それによりkube-dnsサービスに対するクエリー数を減らします。
アーキテクチャー図
この図はNodeLocal DNSキャッシュが有効にされた後にDNSクエリーがあったときの流れとなります。

Nodelocal DNSCacheのフロー
この図は、NodeLocal DNSキャッシュがDNSクエリーをどう扱うかを表したものです。
設定
この機能は、下記の手順により有効化できます。
-
nodelocaldns.yamlと同様のマニフェストを用意し、nodelocaldns.yamlという名前で保存してください。 -
マニフェスト内の変数を正しい値に置き換えてください。
-
kubedns=
kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP} -
domain=
<cluster-domain> -
localdns=
<node-local-address>
<cluster-domain>はデフォルトで"cluster.local"です。<node-local-address>はNodeLocal DNSキャッシュ用に確保されたローカルの待ち受けIPアドレスです。-
kube-proxyがIPTABLESモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yaml__PILLAR__CLUSTER__DNS__と__PILLAR__UPSTREAM__SERVERS__はnode-local-dnsというPodによって生成されます。 このモードでは、node-local-dns Podは<node-local-address>とkube-dnsのサービスIPの両方で待ち受けるため、PodはIPアドレスでもDNSレコードのルップアップができます。 -
kube-proxyがIPVSモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yamlこのモードでは、node-local-dns Podは
<node-local-address>上のみで待ち受けます。node-local-dnsのインターフェースはkube-dnsのクラスターIPをバインドしません。なぜならばIPVSロードバランシング用に使われているインターフェースは既にこのアドレスを使用しているためです。__PILLAR__UPSTREAM__SERVERS__はnode-local-dns Podにより生成されます。
-
-
kubectl create -f nodelocaldns.yamlを実行してください。 -
kube-proxyをIPVSモードで使用しているとき、NodeLocal DNSキャッシュが待ち受けている
<node-local-address>を使用するため、kubeletに対する--cluster-dnsフラグを修正する必要があります。IPVSモード以外のとき、--cluster-dnsフラグの値を修正する必要はありません。なぜならNodeLocal DNSキャッシュはkube-dnsのサービスIPと<node-local-address>の両方で待ち受けているためです。
一度有効にすると、クラスターの各Node上で、kube-systemという名前空間でnode-local-dns Podが、稼働します。このPodはCoreDNSをキャッシュモードで稼働させるため、異なるプラグインによって公開された全てのCoreDNSのメトリクスがNode単位で利用可能となります。
kubectl delete -f <manifest>を実行してDaemonSetを削除することによって、この機能を無効にできます。また、kubeletの設定に対して行った全ての変更をリバートすべきです。
7 - Serviceトポロジーを有効にする
このページでは、Kubernetes上でServiceトポロジーを有効にする方法の概要について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.
はじめに
Serviceトポロジーは、クラスターのノードのトポロジーに基づいてトラフィックをルーティングできるようにする機能です。たとえば、あるServiceのトラフィックに対して、できるだけ同じノードや同じアベイラビリティゾーン上にあるエンドポイントを優先してルーティングするように指定できます。
前提
トポロジーを考慮したServiceのルーティングを有効にするには、以下の前提を満たしている必要があります。
- Kubernetesバージョン1.17以降である
- Kube-proxyがiptableモードまたはIPVSモードで稼働している
- Endpoint Sliceを有効にしている
Serviceトポロジーを有効にする
Kubernetes v1.17 [alpha]
Serviceトポロジーを有効にするには、すべてのKubernetesコンポーネントでServiceTopologyとEndpointSliceフィーチャーゲートを有効にする必要があります。
--feature-gates="ServiceTopology=true,EndpointSlice=true"
次の項目
- Serviceトポロジーのコンセプトについて読む
- Endpoint Sliceについて読む
- サービスとアプリケーションの接続を読む
8 - サービスディスカバリーにCoreDNSを使用する
このページでは、CoreDNSのアップグレードプロセスと、kube-dnsの代わりにCoreDNSをインストールする方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.9. バージョンを確認するには次のコマンドを実行してください:kubectl version.
CoreDNSについて
CoreDNSは、KubernetesクラスターDNSとして稼働させることができる柔軟で拡張可能なDNSサーバーです。Kubernetesと同様に、CoreDNSプロジェクトはCNCFによってホストされています。
既存のデプロイでkube-dnsを置き換えるか、クラスターのデプロイとアップグレードを代行してくれるkubeadmのようなツールを使用することで、クラスターでkube-dnsの代わりにCoreDNSを使用することができます。
CoreDNSのインストール
kube-dnsの手動デプロイや置き換えについては、CoreDNS GitHub projectのドキュメントを参照してください。
CoreDNSへの移行
kubeadmを使用した既存のクラスターのアップグレード
Kubernetesバージョン1.10以降では、kube-dnsを使用しているクラスターをkubeadmを使用してアップグレードするときに、CoreDNSに移行することもできます。この場合、kubeadmは、kube-dns ConfigMapをベースにしてCoreDNS設定("Corefile")を生成し、フェデレーション、スタブドメイン、および上流のネームサーバーの設定を保持します。
kube-dnsからCoreDNSに移行する場合は、アップグレード時に必ずCoreDNSフィーチャーゲートをtrueに設定してください。たとえば、v1.11.0のアップグレードは次のようになります:
kubeadm upgrade apply v1.11.0 --feature-gates=CoreDNS=true
Kubernetesバージョン1.13以降では、CoreDNSフィーチャーゲートが削除され、CoreDNSがデフォルトで使用されます。アップグレードしたクラスターでkube-dnsを使用する場合は、こちらのガイドに従ってください。
1.11以前のバージョンでは、Corefileはアップグレード中に作成されたものによって上書きされます。カスタマイズしている場合は、既存のConfigMapを保存する必要があります。 新しいConfigMapが稼働したら、カスタマイズを再適用できます。
Kubernetesバージョン1.11以降でCoreDNSを実行している場合、アップグレード中、既存のCorefileは保持されます。
kubeadmを使用してCoreDNSの代わりにkube-dnsをインストールする
1.13以前のバージョンにkube-dnsをインストールするには、CoreDNSフィーチャーゲートの値をfalseに設定します:
kubeadm init --feature-gates=CoreDNS=false
バージョン1.13以降の場合は、こちらに記載されているガイドに従ってください。
CoreDNSのアップグレード
CoreDNSはv1.9以降のKubernetesで使用できます。Kubernetesに同梱されているCoreDNSのバージョンと、CoreDNSに加えられた変更はこちらで確認できます。
CoreDNSだけをアップグレードしたい場合や、独自のカスタムイメージを使用したい場合は、CoreDNSを手動でアップグレードすることができます。スムーズなアップグレードのために役立つガイドラインとウォークスルーが用意されています。
CoreDNSのチューニング
リソース使用率が問題になる場合は、CoreDNSの設定を調整すると役立つ場合があります。詳細は、CoreDNSのスケーリングに関するドキュメントを参照してください。
次の項目
CoreDNSは、Corefileを変更することで、kube-dnsよりも多くのユースケースをサポートするように設定することができます。詳細はCoreDNSサイトを参照してください。
9 - ノードのトポロジー管理ポリシーを制御する
Kubernetes v1.18 [beta]
近年、CPUやハードウェア・アクセラレーターの組み合わせによって、レイテンシーが致命的となる実行や高いスループットを求められる並列計算をサポートするシステムが増えています。このようなシステムには、通信、科学技術計算、機械学習、金融サービス、データ分析などの分野のワークロードが含まれます。このようなハイブリッドシステムは、高い性能の環境で構成されます。
最高のパフォーマンスを引き出すために、CPUの分離やメモリーおよびデバイスの位置に関する最適化が求められます。しかしながら、Kubernetesでは、これらの最適化は分断されたコンポーネントによって処理されます。
トポロジーマネージャー はKubeletコンポーネントの1つで最適化の役割を担い、コンポーネント群を調和して機能させます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.18. バージョンを確認するには次のコマンドを実行してください:kubectl version.
トポロジーマネージャーはどのように機能するか
トポロジーマネージャー導入前は、KubernetesにおいてCPUマネージャーやデバイスマネージャーはそれぞれ独立してリソースの割り当てを決定します。 これは、マルチソケットのシステムでは望ましくない割り当てとなり、パフォーマンスやレイテンシーが求められるアプリケーションは、この望ましくない割り当てに悩まされます。 この場合の望ましくない例として、CPUやデバイスが異なるNUMAノードに割り当てられ、それによりレイテンシー悪化を招くことが挙げられます。
トポロジーマネージャーはKubeletコンポーネントであり、信頼できる情報源として振舞います。それによって、他のKubeletコンポーネントはトポロジーに沿ったリソース割り当ての選択を行うことができます。
トポロジーマネージャーは Hint Providers と呼ばれるコンポーネントのインターフェースを提供し、トポロジー情報を送受信します。トポロジーマネージャーは、ノード単位のポリシー群を保持します。ポリシーについて以下で説明します。
トポロジーマネージャーは Hint Providers からトポロジー情報を受け取ります。トポロジー情報は、利用可能なNUMAノードと優先割り当て表示を示すビットマスクです。トポロジーマネージャーのポリシーは、提供されたヒントに対して一連の操作を行い、ポリシーに沿ってヒントをまとめて最適な結果を得ます。もし、望ましくないヒントが保存された場合、ヒントの優先フィールドがfalseに設定されます。現在のポリシーでは、最も狭い優先マスクが優先されます。
選択されたヒントはトポロジーマネージャーの一部として保存されます。設定されたポリシーにしたがい、選択されたヒントに基づいてノードがPodを許可したり、拒否することができます。 トポロジーマネージャーに保存されたヒントは、Hint Providers が使用しリソース割り当てを決定します。
トポロジーマネージャーの機能を有効にする
トポロジーマネージャーをサポートするには、TopologyManager フィーチャーゲートを有効にする必要があります。Kubernetes 1.18ではデフォルトで有効です。
トポロジーマネージャーのスコープとポリシー
トポロジーマネージャは現在:
- 全てのQoAクラスのPodを調整する
- Hint Providerによって提供されたトポロジーヒントから、要求されたリソースを調整する
これらの条件が合致した場合、トポロジーマネージャーは要求されたリソースを調整します。
この調整をどのように実行するかカスタマイズするために、トポロジーマネージャーは2つのノブを提供します: スコープ とポリシーです。
スコープはリソースの配置を行う粒度を定義します(例:podやcontainer)。そして、ポリシーは調整を実行するための実戦略を定義します(best-effort, restricted, single-numa-node等)。
現在利用可能なスコープとポリシーの値について詳細は以下の通りです。
トポロジーマネージャーのスコープ
トポロジーマネージャーは、以下の複数の異なるスコープでリソースの調整を行う事が可能です:
container(デフォルト)pod
いずれのオプションも、--topology-manager-scopeフラグによって、kubelet起動時に選択できます。
containerスコープ
containerスコープはデフォルトで使用されます。
このスコープでは、トポロジーマネージャーは連続した複数のリソース調整を実行します。つまり、Pod内の各コンテナは、分離された配置計算がされます。言い換えると、このスコープでは、コンテナを特定のNUMAノードのセットにグループ化するという概念はありません。実際には、トポロジーマネージャーは各コンテナのNUMAノードへの配置を任意に実行します。
コンテナをグループ化するという概念は、以下のスコープで設定・実行されます。例えば、podスコープが挙げられます。
podスコープ
podスコープを選択するには、コマンドラインで--topology-manager-scope=podオプションを指定してkubeletを起動します。
このスコープでは、Pod内全てのコンテナを共通のNUMAノードのセットにグループ化することができます。トポロジーマネージャーはPodをまとめて1つとして扱い、ポッド全体(全てのコンテナ)を単一のNUMAノードまたはNUMAノードの共通セットのいずれかに割り当てようとします。以下の例は、さまざまな場面でトポロジーマネージャーが実行する調整を示します:
- 全てのコンテナは、単一のNUMAノードに割り当てられます。
- 全てのコンテナは、共有されたNUMAノードのセットに割り当てられます。
Pod全体に要求される特定のリソースの総量は有効なリクエスト/リミットの式に従って計算されるため、この総量の値は以下の最大値となります。
- 全てのアプリケーションコンテナのリクエストの合計。
- リソースに対するinitコンテナのリクエストの最大値。
podスコープとsingle-numa-nodeトポロジーマネージャーポリシーを併用することは、レイテンシーが重要なワークロードやIPCを行う高スループットのアプリケーションに対して特に有効です。両方のオプションを組み合わせることで、Pod内の全てのコンテナを単一のNUMAノードに配置できます。そのため、PodのNUMA間通信によるオーバーヘッドを排除することができます。
single-numa-nodeポリシーの場合、可能な割り当ての中に適切なNUMAノードのセットが存在する場合にのみ、Podが許可されます。上の例をもう一度考えてみましょう:
- 1つのNUMAノードのみを含むセット - Podが許可されます。
- 2つ以上のNUMAノードを含むセット - Podが拒否されます(1つのNUMAノードの代わりに、割り当てを満たすために2つ以上のNUMAノードが必要となるため)。
要約すると、トポロジーマネージャーはまずNUMAノードのセットを計算し、それをトポロジーマネージャーのポリシーと照合し、Podの拒否または許可を検証します。
トポロジーマネージャーのポリシー
トポロジーマネージャーは4つの調整ポリシーをサポートします。--topology-manager-policyというKubeletフラグを通してポリシーを設定できます。
4つのサポートされるポリシーがあります:
none(デフォルト)best-effortrestrictedsingle-numa-node
none ポリシー
これはデフォルトのポリシーで、トポロジーの調整を実行しません。
best-effort ポリシー
Pod内の各コンテナに対して、best-effort トポロジー管理ポリシーが設定されたkubeletは、各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはこれを保存し、Podをノードに許可します。
Hint Providers はこの情報を使ってリソースの割り当てを決定します。
restricted ポリシー
Pod内の各コンテナに対して、restricted トポロジー管理ポリシーが設定されたkubeletは各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはPodをそのノードに割り当てることを拒否します。この結果、PodはPodの受付失敗となりTerminated 状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試み ません 。Podの再デプロイをするためには、ReplicasetかDeploymenを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
Podが許可されれば、 Hint Providers はこの情報を使ってリソースの割り当てを決定します。
single-numa-node ポリシー
Pod内の各コンテナに対して、single-numa-nodeトポロジー管理ポリシーが設定されたkubeletは各Hint Prociderを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、単一のNUMAノードアフィニティが可能かどうか決定します。
可能な場合、トポロジーマネージャーは、この情報を保存し、Hint Providers はこの情報を使ってリソースの割り当てを決定します。
不可能な場合、トポロジーマネージャーは、Podをそのノードに割り当てることを拒否します。この結果、Pod は Pod の受付失敗となりTerminated状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試みません。Podの再デプロイをするためには、ReplicasetかDeploymentを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
Podとトポロジー管理ポリシーの関係
以下のようなpodのSpecで定義されるコンテナを考えます:
spec:
containers:
- name: nginx
image: nginx
requestsもlimitsも定義されていないため、このPodはBestEffortQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
requestsがlimitsより小さい値のため、このPodはBurstableQoSクラスで実行します。
選択されたポリシーがnone以外の場合、トポロジーマネージャーは、これらのPodのSpecを考慮します。トポロジーマネージャーは、Hint Providersからトポロジーヒントを取得します。CPUマネージャーポリシーがstaticの場合、デフォルトのトポロジーヒントを返却します。これらのPodは明示的にCPUリソースを要求していないからです。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
整数値でCPUリクエストを指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
CPUの一部をリクエストで指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
CPUもメモリもリクエスト値がないため、このPodは BestEffort QoSクラスで実行します。
トポロジーマネージャーは、上記Podを考慮します。トポロジーマネージャーは、Hint ProvidersとなるCPUマネージャーとデバイスマネージャーに問い合わせ、トポロジーヒントを取得します。
整数値でCPU要求を指定されたGuaranteedQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、排他的なCPUに関するトポロジーヒントを返却し、デバイスマネージャーは要求されたデバイスのヒントを返します。
CPUの一部を要求を指定されたGuaranteedQoSクラスのPodの場合、排他的ではないCPU要求のためstaticが設定されたCPUマネージャーポリシーはデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスのヒントを返します。
上記のGuaranteedQoSクラスのPodに関する2ケースでは、noneで設定されたCPUマネージャーポリシーは、デフォルトのトポロジーヒントを返却します。
BestEffortQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、CPUの要求がないためデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスごとのヒントを返します。
トポロジーマネージャーはこの情報を使用してPodに最適なヒントを計算し保存します。保存されたヒントは Hint Providersが使用しリソースを割り当てます。
既知の制限
-
トポロジーマネージャーが許容するNUMAノードの最大値は8です。8より多いNUMAノードでは、可能なNUMAアフィニティを列挙しヒントを生成する際に、生成する状態数が爆発的に増加します。
-
スケジューラーはトポロジーを意識しません。そのため、ノードにスケジュールされた後に実行に失敗する可能性があります。
10 - クラウドコントローラーマネージャーの運用管理
Kubernetes v1.11 [beta]
クラウドプロバイダーはKubernetesプロジェクトとは異なるペースで開発およびリリースされるため、プロバイダー固有のコードを`cloud-controller-manager`バイナリに抽象化することでクラウドベンダーはKubernetesのコアのコードとは独立して開発が可能となりました。
cloud-controller-managerは、cloudprovider.Interfaceを満たす任意のクラウドプロバイダーと接続できます。下位互換性のためにKubernetesのコアプロジェクトで提供されるcloud-controller-managerはkube-controller-managerと同じクラウドライブラリを使用します。Kubernetesのコアリポジトリですでにサポートされているクラウドプロバイダーは、Kubernetesリポジトリにあるcloud-controller-managerを使用してKubernetesのコアから移行することが期待されています。
運用
要件
すべてのクラウドには動作させるためにそれぞれのクラウドプロバイダーの統合を行う独自の要件があり、kube-controller-managerを実行する場合の要件とそれほど違わないようにする必要があります。一般的な経験則として、以下のものが必要です。
- クラウドの認証/認可: クラウドではAPIへのアクセスを許可するためにトークンまたはIAMルールが必要になる場合があります
- kubernetesの認証/認可: cloud-controller-managerは、kubernetes apiserverと通信するためにRBACルールの設定を必要とする場合があります
- 高可用性: kube-controller-managerのように、リーダー選出を使用したクラウドコントローラーマネージャーの高可用性のセットアップが必要になる場合があります(デフォルトでオンになっています)。
cloud-controller-managerを動かす
cloud-controller-managerを正常に実行するにはクラスター構成にいくつかの変更が必要です。
kube-apiserverとkube-controller-managerは**--cloud-providerフラグを指定してはいけません**。これによりクラウドコントローラーマネージャーによって実行されるクラウド固有のループが実行されなくなります。将来このフラグは非推奨になり削除される予定です。kubeletは--cloud-provider=externalで実行する必要があります。これは作業をスケジュールする前にクラウドコントローラーマネージャーによって初期化する必要があることをkubeletが認識できるようにするためです。
クラウドコントローラーマネージャーを使用するようにクラスターを設定するとクラスターの動作がいくつか変わることに注意してください。
--cloud-provider=externalを指定したkubeletは、初期化時にNoScheduleのnode.cloudprovider.kubernetes.io/uninitialized汚染を追加します。これによりノードは作業をスケジュールする前に外部のコントローラーからの2回目の初期化が必要であるとマークされます。クラウドコントローラーマネージャーが使用できない場合クラスター内の新しいノードはスケジュールできないままになることに注意してください。スケジューラーはリージョンやタイプ(高CPU、GPU、高メモリ、スポットインスタンスなど)などのノードに関するクラウド固有の情報を必要とする場合があるためこの汚染は重要です。- クラスター内のノードに関するクラウド情報はローカルメタデータを使用して取得されなくなりましたが、代わりにノード情報を取得するためのすべてのAPI呼び出しはクラウドコントローラーマネージャーを経由して行われるようになります。これはセキュリティを向上させるためにkubeletでクラウドAPIへのアクセスを制限できることを意味します。大規模なクラスターではクラスター内からクラウドのほとんどすべてのAPI呼び出しを行うため、クラウドコントローラーマネージャーがレートリミットに達するかどうかを検討する必要があります。
クラウドコントローラーマネージャーは以下を実装できます。
- ノードコントローラー - クラウドAPIを使用してkubernetesノードを更新し、クラウドで削除されたkubernetesノードを削除します。
- サービスコントローラー - タイプLoadBalancerのサービスに対応してクラウド上のロードバランサーを操作します。
- ルートコントローラー - クラウド上でネットワークルートを設定します。
- Kubernetesリポジトリの外部にあるプロバイダーを実行している場合はその他の機能の実装。
例
現在Kubernetesのコアでサポートされているクラウドを使用していて、クラウドコントローラーマネージャーを利用する場合は、kubernetesのコアのクラウドコントローラーマネージャーを参照してください。
Kubernetesのコアリポジトリにないクラウドコントローラーマネージャーの場合、クラウドベンダーまたはsigリードが管理するリポジトリでプロジェクトを見つけることができます。
すでにKubernetesのコアリポジトリにあるプロバイダーの場合、クラスター内でデーモンセットとしてKubernetesリポジトリ内部のクラウドコントローラーマネージャーを実行できます。以下をガイドラインとして使用してください。
# This is an example of how to setup cloud-controller-manager as a Daemonset in your cluster.
# It assumes that your masters can run pods and has the role node-role.kubernetes.io/master
# Note that this Daemonset will not work straight out of the box for your cloud, this is
# meant to be a guideline.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-controller-manager
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:cloud-controller-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: cloud-controller-manager
name: cloud-controller-manager
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: cloud-controller-manager
template:
metadata:
labels:
k8s-app: cloud-controller-manager
spec:
serviceAccountName: cloud-controller-manager
containers:
- name: cloud-controller-manager
# for in-tree providers we use k8s.gcr.io/cloud-controller-manager
# this can be replaced with any other image for out-of-tree providers
image: k8s.gcr.io/cloud-controller-manager:v1.8.0
command:
- /usr/local/bin/cloud-controller-manager
- --cloud-provider=<YOUR_CLOUD_PROVIDER> # Add your own cloud provider here!
- --leader-elect=true
- --use-service-account-credentials
# these flags will vary for every cloud provider
- --allocate-node-cidrs=true
- --configure-cloud-routes=true
- --cluster-cidr=172.17.0.0/16
tolerations:
# this is required so CCM can bootstrap itself
- key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
effect: NoSchedule
# this is to have the daemonset runnable on master nodes
# the taint may vary depending on your cluster setup
- key: node-role.kubernetes.io/master
effect: NoSchedule
# this is to restrict CCM to only run on master nodes
# the node selector may vary depending on your cluster setup
nodeSelector:
node-role.kubernetes.io/master: ""
制限
クラウドコントローラーマネージャーの実行にはいくつかの制限があります。これらの制限は今後のリリースで対処されますが、本番のワークロードにおいてはこれらの制限を認識することが重要です。
ボリュームのサポート
ボリュームの統合にはkubeletとの調整も必要になるためクラウドコントローラーマネージャーはkube-controller-managerにあるボリュームコントローラーを実装しません。CSI(コンテナストレージインターフェイス)が進化してFlexボリュームプラグインの強力なサポートが追加されるにつれ、クラウドがボリュームと完全に統合できるようクラウドコントローラーマネージャーに必要なサポートが追加されます。Kubernetesリポジトリの外部にあるCSIボリュームプラグインの詳細についてはこちらをご覧ください。
スケーラビリティ
cloud-controller-managerは、クラウドプロバイダーのAPIにクエリーを送信して、すべてのノードの情報を取得します。非常に大きなクラスターの場合、リソース要件やAPIレートリミットなどのボトルネックの可能性を考慮する必要があります。
鶏と卵
クラウドコントローラーマネージャープロジェクトの目標はKubernetesのコアプロジェクトからクラウドに関する機能の開発を切り離すことです。残念ながら、Kubernetesプロジェクトの多くの面でクラウドプロバイダーの機能がKubernetesプロジェクトに緊密に結びついているという前提があります。そのため、この新しいアーキテクチャを採用するとクラウドプロバイダーの情報を要求する状況が発生する可能性がありますが、クラウドコントローラーマネージャーはクラウドプロバイダーへのリクエストが完了するまでその情報を返すことができない場合があります。
これの良い例は、KubeletのTLSブートストラップ機能です。TLSブートストラップはKubeletがすべてのアドレスタイプ(プライベート、パブリックなど)をクラウドプロバイダー(またはローカルメタデータサービス)に要求する能力を持っていると仮定していますが、クラウドコントローラーマネージャーは最初に初期化されない限りノードのアドレスタイプを設定できないためapiserverと通信するためにはkubeletにTLS証明書が必要です。
このイニシアチブが成熟するに連れ、今後のリリースでこれらの問題に対処するための変更が行われます。
次の項目
独自のクラウドコントローラーマネージャーを構築および開発するにはクラウドコントローラーマネージャーの開発を参照してください。
11 - クラウドコントローラーマネージャーの開発
cloud-controller-managerは クラウド特有の制御ロジックを組み込むKubernetesのcontrol planeコンポーネントです。クラウドコントロールマネージャーは、クラスターをクラウドプロバイダーAPIをリンクし、クラスタのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離します。
Kubernetesと下のクラウドインフラストラクチャー間の相互運用ロジックを分離することで、cloud-controller-managerコンポーネントはクラウドプロバイダを主なKubernetesプロジェクトと比較し異なるペースで機能をリリース可能にします。
背景
クラウドプロバイダーはKubernetesプロジェクトとは異なる速度で開発しリリースすることから、プロバイダー特有なコードをcloud-controller-managerバイナリから抽象化することで、クラウドベンダーはコアKubernetesコードから独立して発展することができます。
Kubernetesプロジェクトは、(クラウドプロバイダーの)独自実装を組み込めるGoインターフェースを備えたcloud-controller-managerのスケルトンコードを提供しています。これは、クラウドプロバイダーがKubernetesコアからパッケージをインポートすることでcloud-controller-managerを実装できることを意味します。各クラウドプロバイダーは利用可能なクラウドプロバイダーのグローバル変数を更新するためにcloudprovider.RegisterCloudProviderを呼び出し、独自のコードを登録します。
開発
Kubernetesには登録されていない独自クラウドプロバイダー
Kubernetesには登録されていない独自のクラウドプロバイダーのクラウドコントローラーマネージャーを構築するには、
- cloudprovider.Interfaceを満たす go パッケージを実装します。
- Kubernetesのコアにあるcloud-controller-managerの
main.goをあなたのmain.goのテンプレートとして利用します。上で述べたように、唯一の違いはインポートされるクラウドパッケージのみです。 - クラウドパッケージを
main.goにインポートし、パッケージにcloudprovider.RegisterCloudProviderを実行するためのinitブロックがあることを確認します。
多くのクラウドプロバイダーはオープンソースとしてコントローラーマネージャーのコードを公開しています。新たにcloud-controller-managerをスクラッチから開発する際には、既存のKubernetesには登録されていない独自クラウドプロバイダーのコントローラーマネージャーを開始地点とすることができます。
Kubernetesに登録されているクラウドプロバイダー
Kubernetesに登録されているクラウドプロバイダーであれば、DaemonSetを使ってあなたのクラスターで動かすことができます。詳細についてはKubernetesクラウドコントローラーマネージャーを参照してください。
12 - クラスターのセキュリティ
このドキュメントでは、偶発的または悪意のあるアクセスからクラスターを保護するためのトピックについて説明します。 また、全体的なセキュリティに関する推奨事項を提供します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.
Kubernetes APIへのアクセスの制御
Kubernetesは完全にAPI駆動であるため、誰がクラスターにアクセスできるか、どのようなアクションを実行できるかを制御・制限することが第一の防御策となります。
すべてのAPIトラフィックにTLS(Transport Layer Security)を使用する
Kubernetesは、クラスター内のすべてのAPI通信がデフォルトでTLSにより暗号化されていることを期待しており、大半のインストール方法では、必要な証明書を作成してクラスターコンポーネントに配布することができます。
コンポーネントやインストール方法によっては、HTTP上のローカルポートを有効にする場合があることに注意してください。管理者は、潜在的に保護されていないトラフィックを特定するために、各コンポーネントの設定に精通している必要があります。
APIの認証
クラスターのインストール時に、共通のアクセスパターンに合わせて、APIサーバーが使用する認証メカニズムを選択します。 例えば、シングルユーザーの小規模なクラスターでは、シンプルな証明書や静的なBearerトークンを使用することができます。 大規模なクラスターでは、ユーザーをグループに細分化できる既存のOIDCまたはLDAPサーバーを統合することができます。
ノード、プロキシー、スケジューラー、ボリュームプラグインなど、インフラの一部であるものも含めて、すべてのAPIクライアントを認証する必要があります。 これらのクライアントは通常、service accountsであるか、またはx509クライアント証明書を使用しており、クラスター起動時に自動的に作成されるか、クラスターインストールの一部として設定されます。
詳細については、認証を参照してください。
APIの認可
認証されると、すべてのAPIコールは認可チェックを通過することになります。
Kubernetesには、統合されたRBACコンポーネントが搭載されており、入力されたユーザーやグループを、ロールにまとめられたパーミッションのセットにマッチさせます。 これらのパーミッションは、動詞(get, create, delete)とリソース(pods, services, nodes)を組み合わせたもので、ネームスペース・スコープまたはクラスター・スコープに対応しています。 すぐに使えるロールのセットが提供されており、クライアントが実行したいアクションに応じて、デフォルトで適切な責任の分離を提供します。
NodeとRBACの承認者は、NodeRestrictionのアドミッションプラグインと組み合わせて使用することをお勧めします。
認証の場合と同様に、小規模なクラスターにはシンプルで幅広い役割が適切かもしれません。 しかし、より多くのユーザーがクラスターに関わるようになるとチームを別の名前空間に分け、より限定的な役割を持たせることが必要になるかもしれません。 認可においては、あるオブジェクトの更新が、他の場所でどのようなアクションを起こすかを理解することが重要です。
たとえば、ユーザーは直接Podを作成することはできませんが、ユーザーに代わってPodを作成するDeploymentの作成を許可することで、間接的にそれらのPodを作成することができます。 同様に、APIからノードを削除すると、そのノードにスケジューリングされていたPodが終了し、他のノードに再作成されます。 すぐに使えるロールは、柔軟性と一般的なユースケースのバランスを表していますが、より限定的なロールは、偶発的なエスカレーションを防ぐために慎重に検討する必要があります。 すぐに使えるロールがニーズを満たさない場合は、ユースケースに合わせてロールを作成することができます。
詳しくはauthorization reference sectionに参照してください。
Kubeletへのアクセスの制御
Kubeletsは、ノードやコンテナの強力な制御を可能にするHTTPSエンドポイントを公開しています。 デフォルトでは、KubeletsはこのAPIへの認証されていないアクセスを許可しています。
本番環境のクラスターでは、Kubeletの認証と認可を有効にする必要があります。
詳細は、Kubelet 認証/認可に参照してください。
ワークロードやユーザーのキャパシティーを実行時に制御
Kubernetesにおける権限付与は、意図的にハイレベルであり、リソースに対する粗いアクションに焦点を当てています。
より強力なコントロールはpoliciesとして存在し、それらのオブジェクトがクラスタや自身、その他のリソースにどのように作用するかをユースケースによって制限します。
クラスターのリソース使用量の制限
リソースクォータは、ネームスペースに付与されるリソースの数や容量を制限するものです。
これは、ネームスペースが割り当てることのできるCPU、メモリー、永続的なディスクの量を制限するためによく使われますが、各ネームスペースに存在するPod、サービス、ボリュームの数を制御することもできます。
Limit rangesは、上記のリソースの一部の最大または最小サイズを制限することで、ユーザーがメモリーなどの一般的に予約されたリソースに対して不当に高いまたは低い値を要求するのを防いだり、何も指定されていない場合にデフォルトの制限を提供したりします。
コンテナが利用する特権の制御
Podの定義には、security contextが含まれており、ノード上の特定の Linux ユーザー(rootなど)として実行するためのアクセス、特権的に実行するためのアクセス、ホストネットワークにアクセスするためのアクセス、その他の制御を要求することができます。 Pod security policiesは、危険なセキュリティコンテキスト設定を提供できるユーザーやサービスアカウントを制限することができます。
たとえば、Podのセキュリティポリシーでは、ボリュームマウント、特にhostPathを制限することができ、これはPodの制御すべき側面です。
一般に、ほとんどのアプリケーションワークロードでは、ホストリソースへのアクセスを制限する必要があります。
ホスト情報にアクセスすることなく、ルートプロセス(uid 0)として正常に実行できます。
ただし、ルートユーザーに関連する権限を考慮して、非ルートユーザーとして実行するようにアプリケーションコンテナを記述する必要があります。
コンテナが不要なカーネルモジュールをロードしないようにします
Linuxカーネルは、ハードウェアが接続されたときやファイルシステムがマウントされたときなど、特定の状況下で必要となるカーネルモジュールをディスクから自動的にロードします。 特にKubernetesでは、非特権プロセスであっても、適切なタイプのソケットを作成するだけで、特定のネットワークプロトコル関連のカーネルモジュールをロードさせることができます。これにより、管理者が使用されていないと思い込んでいるカーネルモジュールのセキュリティホールを攻撃者が利用できる可能性があります。 特定のモジュールが自動的にロードされないようにするには、そのモジュールをノードからアンインストールしたり、ルールを追加してブロックしたりします。
ほとんどのLinuxディストリビューションでは、/etc/modprobe.d/kubernetes-blacklist.confのような内容のファイルを作成することで実現できます。
# DCCPは必要性が低く、複数の深刻な脆弱性があり、保守も十分ではありません。
blacklist dccp
# SCTPはほとんどのKubernetesクラスタでは使用されておらず、また過去には脆弱性がありました。
blacklist sctp
モジュールのロードをより一般的にブロックするには、SELinuxなどのLinuxセキュリティモジュールを使って、コンテナに対する module_request権限を完全に拒否し、いかなる状況下でもカーネルがコンテナ用のモジュールをロードできないようにすることができます。
(Podは、手動でロードされたモジュールや、より高い権限を持つプロセスに代わってカーネルがロードしたモジュールを使用することはできます)。
ネットワークアクセスの制限
名前空間のネットワークポリシーにより、アプリケーション作成者は、他の名前空間のPodが自分の名前空間内のPodやポートにアクセスすることを制限することができます。
サポートされているKubernetes networking providersの多くは、ネットワークポリシーを尊重するようになりました。 クォータやリミットの範囲は、ユーザーがノードポートや負荷分散サービスを要求するかどうかを制御するためにも使用でき、多くのクラスターでは、ユーザーのアプリケーションがクラスターの外で見えるかどうかを制御できます。 ノードごとのファイアウォール、クロストークを防ぐための物理的なクラスタノードの分離、高度なネットワークポリシーなど、プラグインや環境ごとにネットワークルールを制御する追加の保護機能が利用できる場合もあります。
クラウドメタデータのAPIアクセスを制限
クラウドプラットフォーム(AWS、Azure、GCEなど)では、しばしばメタデータサービスをインスタンスローカルに公開しています。 デフォルトでは、これらのAPIはインスタンス上で実行されているPodからアクセスでき、そのノードのクラウド認証情報や、kubelet認証情報などのプロビジョニングデータを含むことができます。 これらの認証情報は、クラスター内でのエスカレーションや、同じアカウントの他のクラウドサービスへのエスカレーションに使用できます。
クラウドプラットフォーム上でKubernetesを実行する場合は、インスタンスの認証情報に与えられるパーミッションを制限し、ネットワークポリシーを使用してメタデータAPIへのPodのアクセスを制限し、プロビジョニングデータを使用してシークレットを配信することは避けてください。
Podのアクセス可能ノードを制御
デフォルトでは、どのノードがPodを実行できるかについての制限はありません。 Kubernetesは、エンドユーザーが利用できるNode上へのPodのスケジューリングとTaintとTolerationを提供します。 多くのクラスターでは、ワークロードを分離するためにこれらのポリシーを使用することは、作者が採用したり、ツールを使って強制したりする慣習になっています。
管理者としては、ベータ版のアドミッションプラグイン「PodNodeSelector」を使用して、ネームスペース内のPodをデフォルトまたは特定のノードセレクタを必要とするように強制することができます。 エンドユーザーがネームスペースを変更できない場合は、特定のワークロード内のすべてのPodの配置を強く制限することができます。
クラスターのコンポーネントの保護
このセクションでは、クラスターを危険から守るための一般的なパターンを説明します。
etcdへのアクセスの制限
API用のetcdバックエンドへの書き込みアクセスは、クラスタ全体のrootを取得するのと同等であり、読み取りアクセスはかなり迅速にエスカレートするために使用できます。 管理者は、TLSクライアント証明書による相互認証など、APIサーバーからetcdサーバーへの強力な認証情報を常に使用すべきであり、API サーバーのみがアクセスできるファイアウォールの後ろにetcdサーバーを隔離することがしばしば推奨されます。
監査ログの有効
audit loggerはベータ版の機能で、APIによって行われたアクションを記録し、侵害があった場合に後から分析できるようにするものです。
監査ログを有効にして、ログファイルを安全なサーバーにアーカイブすることをお勧めします。
アルファまたはベータ機能へのアクセスの制限
アルファ版およびベータ版のKubernetesの機能は活発に開発が行われており、セキュリティ上の脆弱性をもたらす制限やバグがある可能性があります。 常に、アルファ版またはベータ版の機能が提供する価値と、セキュリティ体制に起こりうるリスクを比較して評価してください。 疑問がある場合は、使用しない機能を無効にしてください。
インフラの認証情報を頻繁に交換
秘密やクレデンシャルの有効期間が短いほど、攻撃者がそのクレデンシャルを利用することは難しくなります。 証明書の有効期間を短く設定し、そのローテーションを自動化します。 発行されたトークンの利用可能期間を制御できる認証プロバイダーを使用し、可能な限り短いライフタイムを使用します。 外部統合でサービス・アカウント・トークンを使用する場合、これらのトークンを頻繁にローテーションすることを計画します。 例えば、ブートストラップ・フェーズが完了したら、ノードのセットアップに使用したブートストラップ・トークンを失効させるか、その認証を解除する必要があります。
サードパーティの統合を有効にする前に確認
Kubernetesへの多くのサードパーティの統合は、クラスターのセキュリティプロファイルを変更する可能性があります。 統合を有効にする際には、アクセスを許可する前に、拡張機能が要求するパーミッションを常に確認してください。
例えば、多くのセキュリティ統合は、事実上そのコンポーネントをクラスター管理者にしているクラスター上のすべての秘密を見るためのアクセスを要求するかもしれません。
疑問がある場合は、可能な限り単一の名前空間で機能するように統合を制限してください。
Podを作成するコンポーネントも、kube-system名前空間のような名前空間内で行うことができれば、予想外に強力になる可能性があります。これは、サービスアカウントのシークレットにアクセスしたり、サービスアカウントに寛容なpod security policiesへのアクセスが許可されている場合に、昇格したパーミッションでPodが実行される可能性があるからです。
etcdにあるSecretを暗号化
一般的に、etcdデータベースにはKubernetes APIを介してアクセス可能なあらゆる情報が含まれており、クラスターの状態に対する大きな可視性を攻撃者へ与える可能性があります。 よく吟味されたバックアップおよび暗号化ソリューションを使用して、常にバックアップを暗号化し、可能な場合はフルディスク暗号化の使用を検討してください。
Kubernetesは1.7で導入された機能であるencryption at restをサポートしており、これは1.13からはベータ版となっています。
これは、etcdのSecretリソースを暗号化し、etcdのバックアップにアクセスした人が、それらのシークレットの内容を見ることを防ぎます。
この機能は現在ベータ版ですが、バックアップが暗号化されていない場合や、攻撃者がetcdへの読み取りアクセスを得た場合に、追加の防御レベルを提供します。
セキュリティアップデートのアラートの受信と脆弱性の報告
kubernetes-announceに参加してください。 グループに参加すると、セキュリティアナウンスに関するメールを受け取ることができます。 脆弱性の報告方法については、security reportingページを参照してください。
13 - ネットワークポリシーを宣言する
このドキュメントでは、Pod同士の通信を制御するネットワークポリシーを定義するための、KubernetesのNetworkPolicy APIを使い始める手助けをします。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.8. バージョンを確認するには次のコマンドを実行してください:kubectl version.
ネットワークポリシーをサポートしているネットワークプロバイダーが設定済みであることを確認してください。さまざまなネットワークプロバイダーがNetworkPolicyをサポートしています。次に挙げるのは一例です。
nginx Deploymentを作成してService経由で公開する
Kubernetesのネットワークポリシーの仕組みを理解するために、まずはnginx Deploymentを作成することから始めましょう。
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
nginxという名前のService経由でDeploymentを公開します。
kubectl expose deployment nginx --port=80
service/nginx exposed
上記のコマンドを実行すると、nginx Podを持つDeploymentが作成され、そのDeploymentがnginxという名前のService経由で公開されます。nginxのPodおよびDeploymentはdefault名前空間の中にあります。
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
もう1つのPodからアクセスしてServiceを検証する
これで、新しいnginxサービスに他のPodからアクセスできるようになったはずです。default名前空間内の他のPodからnginx Serviceにアクセスするために、busyboxコンテナを起動します。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
nginx Serviceへのアクセスを制限する
nginx Serviceへのアクセスを制限するために、access: trueというラベルが付いたPodだけがクエリできるようにします。次の内容でNetworkPolicyオブジェクトを作成してください。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
NetworkPolicyオブジェクトの名前は、有効なDNSサブドメイン名でなければなりません。
podSelectorが含まれています。このポリシーは、ラベルapp=nginxの付いたPodを選択していることがわかります。このラベルは、nginx Deployment内のPodに自動的に追加されたものです。空のpodSelectorは、その名前空間内のすべてのPodを選択します。
Serviceにポリシーを割り当てる
kubectlを使って、上記のnginx-policy.yamlファイルからNetworkPolicyを作成します。
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
accessラベルが定義されていない状態でServiceへのアクセスをテストする
nginx Serviceに正しいラベルが付いていないPodからアクセスを試してみると、リクエストがタイムアウトします。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
accessラベルを定義して再テストする
正しいラベルが付いたPodを作成すると、リクエストが許可されるようになるのがわかります。
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
14 - 拡張リソースをNodeにアドバタイズする
このページでは、Nodeに対して拡張リソースを指定する方法を説明します。拡張リソースを利用すると、Kubernetesにとって未知のノードレベルのリソースをクラスター管理者がアドバタイズできるようになります。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.
Nodeの名前を取得する
kubectl get nodes
この練習で使いたいNodeを1つ選んでください。
Nodeの1つで新しい拡張リソースをアドバタイズする
Node上の新しい拡張リソースをアドバタイズするには、HTTPのPATCHリクエストをKubernetes APIサーバーに送ります。たとえば、Nodeの1つに4つのドングルが接続されているとします。以下に、4つのドングルリソースをNodeにアドバタイズするPATCHリクエストの例を示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/example.com~1dongle",
"value": "4"
}
]
Kubernetesは、ドングルとは何かも、ドングルが何に利用できるのかを知る必要もないことに注意してください。上のPATCHリクエストは、ただNodeが4つのドングルと呼ばれるものを持っているとKubernetesに教えているだけです。
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシーを実行します。
kubectl proxy
もう1つのコマンドウィンドウを開き、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<選択したNodeの名前>/status
~1は、PATCHのパスにおける/という文字をエンコーディングしたものです。JSON-Patch内のoperationのpathはJSON-Pointerとして解釈されます。詳細については、IETF RFC 6901のsection 3を読んでください。
出力には、Nodeがキャパシティー4のdongleを持っていることが示されます。
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
Nodeの説明を確認します。
kubectl describe node <選択したNodeの名前>
出力には、再びdongleリソースが表示されます。
Capacity:
cpu: 2
memory: 2049008Ki
example.com/dongle: 4
これで、アプリケーション開発者は特定の数のdongleをリクエストするPodを作成できるようになりました。詳しくは、拡張リソースをコンテナに割り当てるを読んでください。
議論
拡張リソースは、メモリやCPUリソースと同様のものです。たとえば、Nodeが持っている特定の量のメモリやCPUがNode上で動作している他のすべてのコンポーネントと共有されるのと同様に、Nodeが搭載している特定の数のdongleが他のすべてのコンポーネントと共有されます。そして、アプリケーション開発者が特定の量のメモリとCPUをリクエストするPodを作成できるのと同様に、Nodeが搭載している特定の数のdongleをリクエストするPodが作成できます。
拡張リソースはKubernetesには詳細を意図的に公開しないため、Kubernetesは拡張リソースの実体をまったく知りません。Kubernetesが知っているのは、Nodeが特定の数の拡張リソースを持っているということだけです。拡張リソースは整数値でアドバタイズしなければなりません。たとえば、Nodeは4つのdongleをアドバタイズできますが、4.5のdongleというのはアドバタイズできません。
Storageの例
Nodeに800GiBの特殊なディスクストレージがあるとします。この特殊なストレージの名前、たとえばexample.com/special-storageという名前の拡張リソースが作れます。そして、そのなかの一定のサイズ、たとえば100GiBのチャンクをアドバタイズできます。この場合、Nodeはexample.com/special-storageという種類のキャパシティ8のリソースを持っているとアドバタイズします。
Capacity:
...
example.com/special-storage: 8
特殊なストレージに任意のサイズのリクエストを許可したい場合、特殊なストレージを1バイトのサイズのチャンクでアドバタイズできます。その場合、example.com/special-storageという種類の800Giのリソースとしてアドバタイズします。
Capacity:
...
example.com/special-storage: 800Gi
すると、コンテナは好きなバイト数の特殊なストレージを最大800Giまでリクエストできるようになります。
クリーンアップ
以下に、dongleのアドバタイズをNodeから削除するPATCHリクエストを示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシーを実行します。
kubectl proxy
もう1つのコマンドウィンドウで、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
http://localhost:8001/api/v1/nodes/<選択したNodeの名前>/status
dongleのアドバタイズが削除されたことを検証します。
kubectl describe node <選択したNodeの名前> | grep dongle
(出力には何も表示されないはずです)