安全
- 1: 云原生安全概述
- 2: Pod 安全性标准
- 3: Pod 安全性准入
- 4: Pod 安全策略
- 5: Windows 节点的安全性
- 6: Kubernetes API 访问控制
- 7: 基于角色的访问控制良好实践
- 8: Kubernetes Secret 良好实践
- 9: 多租户
- 10: Kubernetes API 服务器旁路风险
- 11: 安全检查清单
1 - 云原生安全概述
本概述定义了一个模型,用于在 Cloud Native 安全性上下文中考虑 Kubernetes 安全性。
云原生安全的 4 个 C
你可以分层去考虑安全性,云原生安全的 4 个 C 分别是云(Cloud)、集群(Cluster)、容器(Container)和代码(Code)。
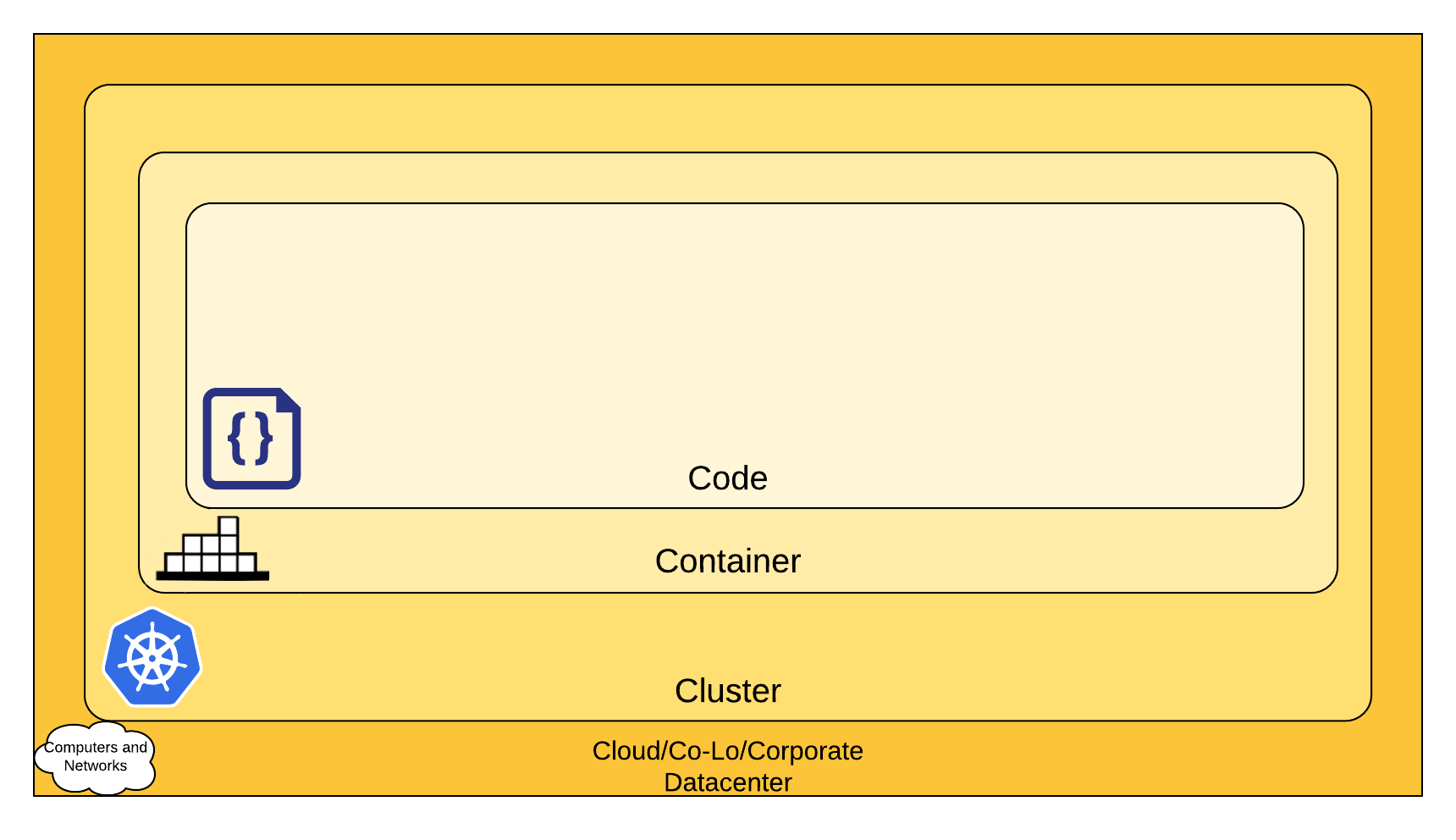
云原生安全的 4C
云原生安全模型的每一层都是基于下一个最外层,代码层受益于强大的基础安全层(云、集群、容器)。 你无法通过在代码层解决安全问题来为基础层中糟糕的安全标准提供保护。
云
在许多方面,云(或者位于同一位置的服务器,或者是公司数据中心)是 Kubernetes 集群中的 可信计算基。 如果云层容易受到攻击(或者被配置成了易受攻击的方式),就不能保证在此基础之上构建的组件是安全的。 每个云提供商都会提出安全建议,以在其环境中安全地运行工作负载。
云提供商安全性
如果你是在你自己的硬件或者其他不同的云提供商上运行 Kubernetes 集群, 请查阅相关文档来获取最好的安全实践。
下面是一些比较流行的云提供商的安全性文档链接:
| IaaS 提供商 | 链接 |
|---|---|
| Alibaba Cloud | https://www.alibabacloud.com/trust-center |
| Amazon Web Services | https://aws.amazon.com/security |
| Google Cloud Platform | https://cloud.google.com/security |
| Huawei Cloud | https://www.huaweicloud.com/securecenter/overallsafety |
| IBM Cloud | https://www.ibm.com/cloud/security |
| Microsoft Azure | https://docs.microsoft.com/en-us/azure/security/azure-security |
| Oracle Cloud Infrastructure | https://www.oracle.com/security |
| VMWare VSphere | https://www.vmware.com/security/hardening-guides |
基础设施安全
关于在 Kubernetes 集群中保护你的基础设施的建议:
| Kubernetes 基础架构关注领域 | 建议 |
|---|---|
| 通过网络访问 API 服务(控制平面) | 所有对 Kubernetes 控制平面的访问不允许在 Internet 上公开,同时应由网络访问控制列表控制,该列表包含管理集群所需的 IP 地址集。 |
| 通过网络访问 Node(节点) | 节点应配置为 仅能 从控制平面上通过指定端口来接受(通过网络访问控制列表)连接,以及接受 NodePort 和 LoadBalancer 类型的 Kubernetes 服务连接。如果可能的话,这些节点不应完全暴露在公共互联网上。 |
| Kubernetes 访问云提供商的 API | 每个云提供商都需要向 Kubernetes 控制平面和节点授予不同的权限集。为集群提供云提供商访问权限时,最好遵循对需要管理的资源的最小特权原则。Kops 文档提供有关 IAM 策略和角色的信息。 |
| 访问 etcd | 对 etcd(Kubernetes 的数据存储)的访问应仅限于控制平面。根据配置情况,你应该尝试通过 TLS 来使用 etcd。更多信息可以在 etcd 文档中找到。 |
| etcd 加密 | 在所有可能的情况下,最好对所有存储进行静态数据加密,并且由于 etcd 拥有整个集群的状态(包括机密信息),因此其磁盘更应该进行静态数据加密。 |
集群
保护 Kubernetes 有两个方面需要注意:
- 保护可配置的集群组件
- 保护在集群中运行的应用程序
集群组件
如果想要保护集群免受意外或恶意的访问,采取良好的信息管理实践,请阅读并遵循有关保护集群的建议。
集群中的组件(你的应用)
根据你的应用程序的受攻击面,你可能需要关注安全性的特定面,比如: 如果你正在运行中的一个服务(A 服务)在其他资源链中很重要,并且所运行的另一工作负载(服务 B) 容易受到资源枯竭的攻击,则如果你不限制服务 B 的资源的话,损害服务 A 的风险就会很高。 下表列出了安全性关注的领域和建议,用以保护 Kubernetes 中运行的工作负载:
| 工作负载安全性关注领域 | 建议 |
|---|---|
| RBAC 授权(访问 Kubernetes API) | https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/rbac/ |
| 认证方式 | https://kubernetes.io/zh-cn/docs/concepts/security/controlling-access/ |
| 应用程序 Secret 管理 (并在 etcd 中对其进行静态数据加密) | https://kubernetes.io/zh-cn/docs/concepts/configuration/secret/ https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/encrypt-data/ |
| 确保 Pod 符合定义的 Pod 安全标准 | https://kubernetes.io/zh-cn/docs/concepts/security/pod-security-standards/#policy-instantiation |
| 服务质量(和集群资源管理) | https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/quality-service-pod/ |
| 网络策略 | https://kubernetes.io/zh-cn/docs/concepts/services-networking/network-policies/ |
| Kubernetes Ingress 的 TLS 支持 | https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress/#tls |
容器
容器安全性不在本指南的探讨范围内。下面是一些探索此主题的建议和连接:
| 容器关注领域 | 建议 |
|---|---|
| 容器漏洞扫描和操作系统依赖安全性 | 作为镜像构建的一部分,你应该扫描你的容器里的已知漏洞。 |
| 镜像签名和执行 | 对容器镜像进行签名,以维护对容器内容的信任。 |
| 禁止特权用户 | 构建容器时,请查阅文档以了解如何在具有最低操作系统特权级别的容器内部创建用户,以实现容器的目标。 |
| 使用带有较强隔离能力的容器运行时 | 选择提供较强隔离能力的容器运行时类。 |
代码
应用程序代码是你最能够控制的主要攻击面之一,虽然保护应用程序代码不在 Kubernetes 安全主题范围内,但以下是保护应用程序代码的建议:
代码安全性
| 代码关注领域 | 建议 |
|---|---|
| 仅通过 TLS 访问 | 如果你的代码需要通过 TCP 通信,请提前与客户端执行 TLS 握手。除少数情况外,请加密传输中的所有内容。更进一步,加密服务之间的网络流量是一个好主意。这可以通过被称为双向 TLS 或 mTLS 的过程来完成,该过程对两个证书持有服务之间的通信执行双向验证。 |
| 限制通信端口范围 | 此建议可能有点不言自明,但是在任何可能的情况下,你都只应公开服务上对于通信或度量收集绝对必要的端口。 |
| 第三方依赖性安全 | 最好定期扫描应用程序的第三方库以了解已知的安全漏洞。每种编程语言都有一个自动执行此检查的工具。 |
| 静态代码分析 | 大多数语言都提供给了一种方法,来分析代码段中是否存在潜在的不安全的编码实践。只要有可能,你都应该使用自动工具执行检查,该工具可以扫描代码库以查找常见的安全错误,一些工具可以在以下连接中找到: https://owasp.org/www-community/Source_Code_Analysis_Tools |
| 动态探测攻击 | 你可以对服务运行一些自动化工具,来尝试一些众所周知的服务攻击。这些攻击包括 SQL 注入、CSRF 和 XSS。OWASP Zed Attack 代理工具是最受欢迎的动态分析工具之一。 |
接下来
学习了解相关的 Kubernetes 安全主题:
2 - Pod 安全性标准
Pod 安全性标准定义了三种不同的 策略(Policy),以广泛覆盖安全应用场景。 这些策略是 叠加式的(Cumulative),安全级别从高度宽松至高度受限。 本指南概述了每个策略的要求。
| Profile | 描述 |
|---|---|
| Privileged | 不受限制的策略,提供最大可能范围的权限许可。此策略允许已知的特权提升。 |
| Baseline | 限制性最弱的策略,禁止已知的策略提升。允许使用默认的(规定最少)Pod 配置。 |
| Restricted | 限制性非常强的策略,遵循当前的保护 Pod 的最佳实践。 |
Profile 细节
Privileged
Privileged 策略是有目的地开放且完全无限制的策略。 此类策略通常针对由特权较高、受信任的用户所管理的系统级或基础设施级负载。
Privileged 策略定义中限制较少。默认允许的(Allow-by-default)实施机制(例如 gatekeeper) 可以缺省设置为 Privileged。 与此不同,对于默认拒绝(Deny-by-default)的实施机制(如 Pod 安全策略)而言, Privileged 策略应该禁止所有限制。
Baseline
Baseline 策略的目标是便于常见的容器化应用采用,同时禁止已知的特权提升。 此策略针对的是应用运维人员和非关键性应用的开发人员。 下面列举的控制应该被实施(禁止):
在下述表格中,通配符(*)意味着一个列表中的所有元素。
例如 spec.containers[*].securityContext 表示 所定义的所有容器 的安全性上下文对象。
如果所列出的任一容器不能满足要求,整个 Pod 将无法通过校验。
| 控制(Control) | 策略(Policy) |
| HostProcess |
Windows Pod 提供了运行 HostProcess 容器 的能力,这使得对 Windows 节点的特权访问成为可能。Baseline 策略中禁止对宿主的特权访问。
特性状态:
Kubernetes v1.23 [beta]
限制的字段
准许的取值
|
| 宿主名字空间 |
必须禁止共享宿主上的名字空间。 限制的字段
准许的取值
|
| 特权容器 |
特权 Pod 会使大多数安全性机制失效,必须被禁止。 限制的字段
准许的取值
|
| 权能 |
必须禁止添加除下列字段之外的权能。 限制的字段
准许的取值
|
| HostPath 卷 |
必须禁止 HostPath 卷。 限制的字段
准许的取值
|
| 宿主端口 |
应该禁止使用宿主端口,或者至少限制只能使用某确定列表中的端口。 限制的字段
准许的取值
|
| AppArmor |
在受支持的主机上,默认使用 限制的字段
准许的取值
|
| SELinux |
设置 SELinux 类型的操作是被限制的,设置自定义的 SELinux 用户或角色选项是被禁止的。 限制的字段
准许的取值
限制的字段
准许的取值
|
/proc挂载类型 |
要求使用默认的 限制的字段
准许的取值
|
| Seccomp |
Seccomp 配置必须不能显式设置为 限制的字段
准许的取值
|
| Sysctls |
Sysctls 可以禁用安全机制或影响宿主上所有容器,因此除了若干“安全”的子集之外,应该被禁止。如果某 sysctl 是受容器或 Pod 的名字空间限制,且与节点上其他 Pod 或进程相隔离,可认为是安全的。 限制的字段
准许的取值
|
Restricted
Restricted 策略旨在实施当前保护 Pod 的最佳实践,尽管这样作可能会牺牲一些兼容性。 该类策略主要针对运维人员和安全性很重要的应用的开发人员,以及不太被信任的用户。 下面列举的控制需要被实施(禁止):
在下述表格中,通配符(*)意味着一个列表中的所有元素。
例如 spec.containers[*].securityContext 表示 所定义的所有容器 的安全性上下文对象。
如果所列出的任一容器不能满足要求,整个 Pod 将无法通过校验。
| 控制 | 策略 |
| Baseline 策略的所有要求。 | |
| 卷类型 |
除了限制 HostPath 卷之外,此类策略还限制可以通过 PersistentVolumes 定义的非核心卷类型。 限制的字段
准许的取值 spec.volumes[*] 列表中的每个条目必须将下面字段之一设置为非空值:
|
| 特权提升(v1.8+) |
禁止(通过 SetUID 或 SetGID 文件模式)获得特权提升。这是 v1.25+ 中仅针对 Linux 的策略 限制的字段
允许的取值
|
| 以非 root 账号运行 |
容器必须以非 root 账号运行。 限制的字段
准许的取值
spec.securityContext.runAsNonRoot 设置为 true,则允许容器组的安全上下文字段设置为 未定义/nil。
|
| 非 root 用户(v1.23+) |
容器不可以将 runAsUser 设置为 0 限制的字段
准许的取值
|
| Seccomp (v1.19+) |
Seccomp Profile 必须被显式设置成一个允许的值。禁止使用 限制的字段
准许的取值
spec.securityContext.seccompProfile.type
已设置得当,容器级别的安全上下文字段可以为未定义/nil。
反之如果 nil。
|
| 权能(v1.22+) |
容器必须弃用 限制的字段
准许的取值
限制的字段
准许的取值
|
策略实例化
将策略定义从策略实例中解耦出来有助于形成跨集群的策略理解和语言陈述, 以免绑定到特定的下层实施机制。
随着相关机制的成熟,这些机制会按策略分别定义在下面。特定策略的实施方法不在这里定义。
替代方案
在 Kubernetes 生态系统中还在开发一些其他的替代方案,例如:
Pod OS 字段
Kubernetes 允许你使用运行 Linux 或 Windows 的节点。你可以在一个集群中混用两种类型的节点。
Kubernetes 中的 Windows 与基于 Linux 的工作负载相比有一些限制和差异。
具体而言,许多 Pod securityContext
字段在 Windows 上不起作用。
v1.24 之前的 Kubelet 不强制处理 Pod OS 字段,如果集群中有些节点运行早于 v1.24 的版本, 则应将限制性的策略锁定到 v1.25 之前的版本。
限制性的 Pod Security Standard 变更
Kubernetes v1.25 中的另一个重要变化是 限制性的(Restricted) Pod 安全性已更新,
能够处理 pod.spec.os.name 字段。根据 OS 名称,专用于特定 OS 的某些策略对其他 OS 可以放宽限制。
OS 特定的策略控制
仅当 .spec.os.name 不是 windows 时,才需要对以下控制进行限制:
- 特权提升
- Seccomp
- Linux 权能
常见问题
为什么不存在介于 Privileged 和 Baseline 之间的策略类型
这里定义的三种策略框架有一个明晰的线性递进关系,从最安全(Restricted)到最不安全, 并且覆盖了很大范围的工作负载。特权要求超出 Baseline 策略者通常是特定于应用的需求, 所以我们没有在这个范围内提供标准框架。 这并不意味着在这样的情形下仍然只能使用 Privileged 框架, 只是说处于这个范围的策略需要因地制宜地定义。
SIG Auth 可能会在将来考虑这个范围的框架,前提是有对其他框架的需求。
安全配置与安全上下文的区别是什么?
安全上下文在运行时配置 Pod 和容器。安全上下文是在 Pod 清单中作为 Pod 和容器规约的一部分来定义的, 所代表的是传递给容器运行时的参数。
安全策略则是控制面用来对安全上下文以及安全性上下文之外的参数实施某种设置的机制。 在 2020 年 7 月, Pod 安全性策略已被废弃, 取而代之的是内置的 Pod 安全性准入控制器。
沙箱(Sandboxed)Pod 怎么处理?
现在还没有 API 标准来控制 Pod 是否被视作沙箱化 Pod。 沙箱 Pod 可以通过其是否使用沙箱化运行时(如 gVisor 或 Kata Container)来辨别, 不过目前还没有关于什么是沙箱化运行时的标准定义。
沙箱化负载所需要的保护可能彼此各不相同。例如,当负载与下层内核直接隔离开来时, 限制特权化操作的许可就不那么重要。这使得那些需要更多许可权限的负载仍能被有效隔离。
此外,沙箱化负载的保护高度依赖于沙箱化的实现方法。 因此,现在还没有针对所有沙箱化负载的建议配置。
3 - Pod 安全性准入
Kubernetes v1.25 [stable]
Kubernetes Pod 安全性标准(Security Standards) 为 Pod 定义不同的隔离级别。这些标准能够让你以一种清晰、一致的方式定义如何限制 Pod 行为。
Kubernetes 提供了一个内置的 Pod Security 准入控制器来执行 Pod 安全标准 (Pod Security Standard)。 创建 Pod 时在名字空间级别应用这些 Pod 安全限制。
内置 Pod 安全准入强制执行
本页面是 Kubernetes v1.25 文档的一部分。 如果你运行的是其他版本的 Kubernetes,请查阅该版本的文档。
Pod 安全性级别
Pod 安全性准入插件对 Pod
的安全性上下文有一定的要求,
并且依据 Pod 安全性标准所定义的三个级别
(privileged、baseline 和 restricted)对其他字段也有要求。
关于这些需求的更进一步讨论,请参阅
Pod 安全性标准页面。
为名字空间设置 Pod 安全性准入控制标签
一旦特性被启用或者安装了 Webhook,你可以配置名字空间以定义每个名字空间中 Pod 安全性准入控制模式。 Kubernetes 定义了一组标签, 你可以设置这些标签来定义某个名字空间上要使用的预定义的 Pod 安全性标准级别。 你所选择的标签定义了检测到潜在违例时, 控制面要采取什么样的动作。
| 模式 | 描述 |
|---|---|
| enforce | 策略违例会导致 Pod 被拒绝 |
| audit | 策略违例会触发审计日志中记录新事件时添加审计注解;但是 Pod 仍是被接受的。 |
| warn | 策略违例会触发用户可见的警告信息,但是 Pod 仍是被接受的。 |
名字空间可以配置任何一种或者所有模式,或者甚至为不同的模式设置不同的级别。
对于每种模式,决定所使用策略的标签有两个:
# 模式的级别标签用来标示对应模式所应用的策略级别
#
# MODE 必须是 `enforce`、`audit` 或 `warn` 之一
# LEVEL 必须是 `privileged`、baseline` 或 `restricted` 之一
pod-security.kubernetes.io/<MODE>: <LEVEL>
# 可选:针对每个模式版本的版本标签可以将策略锁定到
# 给定 Kubernetes 小版本号所附带的版本(例如 v1.25)
#
# MODE 必须是 `enforce`、`audit` 或 `warn` 之一
# VERSION 必须是一个合法的 Kubernetes 小版本号或者 `latest`
pod-security.kubernetes.io/<MODE>-version: <VERSION>
关于用法示例,可参阅使用名字空间标签来强制实施 Pod 安全标准。
负载资源和 Pod 模板
Pod 通常是通过创建 Deployment 或
Job
这类工作负载对象
来间接创建的。工作负载对象为工作负载资源定义一个 Pod 模板
和一个对应的负责基于该模板来创建 Pod 的控制器。
为了尽早地捕获违例状况,audit 和 warn 模式都应用到负载资源。
不过,enforce 模式并 不 应用到工作负载资源,仅应用到所生成的 Pod 对象上。
豁免
你可以为 Pod 安全性的实施设置 豁免(Exemptions) 规则, 从而允许创建一些本来会被与给定名字空间相关的策略所禁止的 Pod。 豁免规则可以在准入控制器配置 中静态配置。
豁免规则可以显式枚举。满足豁免标准的请求会被准入控制器 忽略
(所有 enforce、audit 和 warn 行为都会被略过)。
豁免的维度包括:
- Username: 来自用户名已被豁免的、已认证的(或伪装的)的用户的请求会被忽略。
- RuntimeClassName: 指定了已豁免的运行时类名称的 Pod 和负载资源会被忽略。
- Namespace: 位于被豁免的名字空间中的 Pod 和负载资源会被忽略。
大多数 Pod 是作为对工作负载资源的响应,
由控制器所创建的,这意味着为某最终用户提供豁免时,只会当该用户直接创建 Pod
时对其实施安全策略的豁免。用户创建工作负载资源时不会被豁免。
控制器服务账号(例如:system:serviceaccount:kube-system:replicaset-controller)
通常不应该被豁免,因为豁免这类服务账号隐含着对所有能够创建对应工作负载资源的用户豁免。
策略检查时会对以下 Pod 字段的更新操作予以豁免,这意味着如果 Pod 更新请求仅改变这些字段时,即使 Pod 违反了当前的策略级别,请求也不会被拒绝。
- 除了对 seccomp 或 AppArmor 注解之外的所有元数据(Metadata)更新操作:
seccomp.security.alpha.kubernetes.io/pod(已弃用)container.seccomp.security.alpha.kubernetes.io/*(已弃用)container.apparmor.security.beta.kubernetes.io/*
- 对
.spec.activeDeadlineSeconds的合法更新 - 对
.spec.tolerations的合法更新
接下来
4 - Pod 安全策略
被移除的特性
PodSecurityPolicy 在 Kubernetes v1.21 中被弃用, 在 Kubernetes v1.25 中被移除。
作为替代,你可以使用下面任一方式执行类似的限制,或者同时使用下面这两种方式。
- Pod 安全准入
- 自行部署并配置第三方准入插件
有关如何迁移, 参阅从 PodSecurityPolicy 迁移到内置的 PodSecurity 准入控制器。 有关移除此 API 的更多信息,参阅 弃用 PodSecurityPolicy:过去、现在、未来。
如果所运行的 Kubernetes 不是 v1.25 版本,则需要查看你所使用的 Kubernetes 版本的对应文档。
5 - Windows 节点的安全性
本篇介绍特定于 Windows 操作系统的安全注意事项和最佳实践。
保护节点上的 Secret 数据
在 Windows 上,来自 Secret 的数据以明文形式写入节点的本地存储 (与在 Linux 上使用 tmpfs / 内存中文件系统不同)。 作为集群操作员,你应该采取以下两项额外措施:
- 使用文件 ACL 来保护 Secret 的文件位置。
- 使用 BitLocker 进行卷级加密。
容器用户
可以为 Windows Pod 或容器指定 RunAsUsername 以作为特定用户执行容器进程。这大致相当于 RunAsUser。
Windows 容器提供两个默认用户帐户,ContainerUser 和 ContainerAdministrator。 在微软的 Windows 容器安全 文档 何时使用 ContainerAdmin 和 ContainerUser 用户帐户 中介绍了这两个用户帐户之间的区别。
在容器构建过程中,可以将本地用户添加到容器镜像中。
- 基于 Nano Server 的镜像默认以
ContainerUser运行 - 基于 Server Core 的镜像默认以
ContainerAdministrator运行
Windows 容器还可以通过使用组管理的服务账号作为 Active Directory 身份运行。
Pod 级安全隔离
Windows 节点不支持特定于 Linux 的 Pod 安全上下文机制(例如 SELinux、AppArmor、Seccomp 或自定义 POSIX 权能字)。
Windows 上不支持特权容器。 然而,可以在 Windows 上使用 HostProcess 容器来执行 Linux 上特权容器执行的许多任务。
6 - Kubernetes API 访问控制
本页面概述了对 Kubernetes API 的访问控制。
用户使用 kubectl、客户端库或构造 REST 请求来访问 Kubernetes API。
人类用户和 Kubernetes 服务账户都可以被鉴权访问 API。
当请求到达 API 时,它会经历多个阶段,如下图所示:

传输安全
默认情况下,Kubernetes API 服务器在第一个非 localhost 网络接口的 6443 端口上进行监听,
受 TLS 保护。在一个典型的 Kubernetes 生产集群中,API 使用 443 端口。
该端口可以通过 --secure-port 进行变更,监听 IP 地址可以通过 --bind-address 标志进行变更。
API 服务器出示证书。该证书可以使用私有证书颁发机构(CA)签名,也可以基于链接到公认的 CA 的公钥基础架构签名。
该证书和相应的私钥可以通过使用 --tls-cert-file 和 --tls-private-key-file 标志进行设置。
如果你的集群使用私有证书颁发机构,你需要在客户端的 ~/.kube/config 文件中提供该 CA 证书的副本,
以便你可以信任该连接并确认该连接没有被拦截。
你的客户端可以在此阶段出示 TLS 客户端证书。
认证
如上图步骤 1 所示,建立 TLS 后, HTTP 请求将进入认证(Authentication)步骤。 集群创建脚本或者集群管理员配置 API 服务器,使之运行一个或多个身份认证组件。 身份认证组件在认证节中有更详细的描述。
认证步骤的输入整个 HTTP 请求;但是,通常组件只检查头部或/和客户端证书。
认证模块包含客户端证书、密码、普通令牌、引导令牌和 JSON Web 令牌(JWT,用于服务账户)。
可以指定多个认证模块,在这种情况下,服务器依次尝试每个验证模块,直到其中一个成功。
如果请求认证不通过,服务器将以 HTTP 状态码 401 拒绝该请求。
反之,该用户被认证为特定的 username,并且该用户名可用于后续步骤以在其决策中使用。
部分验证器还提供用户的组成员身份,其他则不提供。
鉴权
如上图的步骤 2 所示,将请求验证为来自特定的用户后,请求必须被鉴权。
请求必须包含请求者的用户名、请求的行为以及受该操作影响的对象。 如果现有策略声明用户有权完成请求的操作,那么该请求被鉴权通过。
例如,如果 Bob 有以下策略,那么他只能在 projectCaribou 名称空间中读取 Pod。
{
"apiVersion": "abac.authorization.kubernetes.io/v1beta1",
"kind": "Policy",
"spec": {
"user": "bob",
"namespace": "projectCaribou",
"resource": "pods",
"readonly": true
}
}
如果 Bob 执行以下请求,那么请求会被鉴权,因为允许他读取 projectCaribou 名称空间中的对象。
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "projectCaribou",
"verb": "get",
"group": "unicorn.example.org",
"resource": "pods"
}
}
}
如果 Bob 在 projectCaribou 名字空间中请求写(create 或 update)对象,其鉴权请求将被拒绝。
如果 Bob 在诸如 projectFish 这类其它名字空间中请求读取(get)对象,其鉴权也会被拒绝。
Kubernetes 鉴权要求使用公共 REST 属性与现有的组织范围或云提供商范围的访问控制系统进行交互。 使用 REST 格式很重要,因为这些控制系统可能会与 Kubernetes API 之外的 API 交互。
Kubernetes 支持多种鉴权模块,例如 ABAC 模式、RBAC 模式和 Webhook 模式等。 管理员创建集群时,他们配置应在 API 服务器中使用的鉴权模块。 如果配置了多个鉴权模块,则 Kubernetes 会检查每个模块,任意一个模块鉴权该请求,请求即可继续; 如果所有模块拒绝了该请求,请求将会被拒绝(HTTP 状态码 403)。
要了解更多有关 Kubernetes 鉴权的更多信息,包括有关使用支持鉴权模块创建策略的详细信息, 请参阅鉴权。
准入控制
准入控制模块是可以修改或拒绝请求的软件模块。 除鉴权模块可用的属性外,准入控制模块还可以访问正在创建或修改的对象的内容。
准入控制器对创建、修改、删除或(通过代理)连接对象的请求进行操作。 准入控制器不会对仅读取对象的请求起作用。 有多个准入控制器被配置时,服务器将依次调用它们。
这一操作如上图的步骤 3 所示。
与身份认证和鉴权模块不同,如果任何准入控制器模块拒绝某请求,则该请求将立即被拒绝。
除了拒绝对象之外,准入控制器还可以为字段设置复杂的默认值。
可用的准入控制模块在准入控制器中进行了描述。
请求通过所有准入控制器后,将使用检验例程检查对应的 API 对象,然后将其写入对象存储(如步骤 4 所示)。
审计
Kubernetes 审计提供了一套与安全相关的、按时间顺序排列的记录,其中记录了集群中的操作序列。 集群对用户、使用 Kubernetes API 的应用程序以及控制平面本身产生的活动进行审计。
更多信息请参考审计。
接下来
阅读更多有关身份认证、鉴权和 API 访问控制的文档:
你可以了解
- Pod 如何使用 Secrets 获取 API 凭证。
7 - 基于角色的访问控制良好实践
Kubernetes RBAC 是一项重要的安全控制措施,用于保证集群用户和工作负载只能访问履行自身角色所需的资源。 在为集群用户设计权限时,请务必确保集群管理员知道可能发生特权提级的地方, 降低因过多权限而导致安全事件的风险。
此文档的良好实践应该与通用 RBAC 文档一起阅读。
通用的良好实践
最小特权
理想情况下,分配给用户和服务帐户的 RBAC 权限应该是最小的。 仅应使用操作明确需要的权限,虽然每个集群会有所不同,但可以应用的一些常规规则:
- 尽可能在命名空间级别分配权限。授予用户在特定命名空间中的权限时使用 RoleBinding 而不是 ClusterRoleBinding。
- 尽可能避免通过通配符设置权限,尤其是对所有资源的权限。 由于 Kubernetes 是一个可扩展的系统,因此通过通配符来授予访问权限不仅会授予集群中当前的所有对象类型, 还包含所有未来被创建的所有对象类型。
- 管理员不应使用
cluster-admin账号,除非特别需要。为低特权帐户提供 伪装权限 可以避免意外修改集群资源。 - 避免将用户添加到
system:masters组。任何属于此组成员的用户都会绕过所有 RBAC 权限检查, 始终具有不受限制的超级用户访问权限,并且不能通过删除RoleBinding或ClusterRoleBinding来取消其权限。顺便说一句,如果集群使用 Webhook 鉴权,此组的成员身份也会绕过该 Webhook(来自属于该组成员的用户的请求永远不会发送到 Webhook)。
最大限度地减少特权令牌的分发
理想情况下,不应为 Pod 分配具有强大权限(例如,在特权提级的风险中列出的任一权限)的服务帐户。 如果工作负载需要比较大的权限,请考虑以下做法:
- 限制运行此类 Pod 的节点数量。确保你运行的任何 DaemonSet 都是必需的, 并且以最小权限运行,以限制容器逃逸的影响范围。
- 避免将此类 Pod 与不可信任或公开的 Pod 在一起运行。 考虑使用污点和容忍度、 节点亲和性或 Pod 反亲和性确保 Pod 不会与不可信或不太受信任的 Pod 一起运行。 特别注意可信度不高的 Pod 不符合 Restricted Pod 安全标准的情况。
加固
Kubernetes 默认提供访问权限并非是每个集群都需要的。
审查默认提供的 RBAC 权限为安全加固提供了机会。
一般来说,不应该更改 system: 帐户的某些权限,有一些方式来强化现有集群的权限:
- 审查
system:unauthenticated组的绑定,并在可能的情况下将其删除, 因为这会给所有能够访问 API 服务器的人以网络级别的权限。 - 通过设置
automountServiceAccountToken: false来避免服务账号令牌的默认自动挂载, 有关更多详细信息,请参阅使用默认服务账号令牌。 此参数可覆盖 Pod 服务账号设置,而需要服务账号令牌的工作负载仍可以挂载。
定期检查
定期检查 Kubernetes RBAC 设置是否有冗余条目和提权可能性是至关重要的。 如果攻击者能够创建与已删除用户同名的用户账号, 他们可以自动继承被删除用户的所有权限,尤其是分配给该用户的权限。
Kubernetes RBAC - 权限提权的风险
在 Kubernetes RBAC 中有许多特权,如果被授予, 用户或服务帐户可以提升其在集群中的权限并可能影响集群外的系统。
本节旨在提醒集群操作员需要注意的不同领域, 以确保他们不会无意中授予超出预期的集群访问权限。
列举 Secret
大家都很清楚,若允许对 Secrets 执行 get 访问,用户就获得了访问 Secret 内容的能力。
同样需要注意的是:list 和 watch 访问也会授权用户获取 Secret 的内容。
例如,当返回 List 响应时(例如,通过
kubectl get secrets -A -o yaml),响应包含所有 Secret 的内容。
工作负载的创建
在一个命名空间中创建工作负载(Pod 或管理 Pod 的工作负载资源) 的权限隐式地授予了对该命名空间中许多其他资源的访问权限,例如可以挂载在 Pod 中的 Secret、ConfigMap 和 PersistentVolume。 此外,由于 Pod 可以被任何服务账号运行, 因此授予创建工作负载的权限也会隐式地授予该命名空间中任何服务账号的 API 访问级别。
可以运行特权 Pod 的用户可以利用该访问权限获得节点访问权限, 并可能进一步提升他们的特权。如果你不完全信任某用户或其他主体, 不相信他们能够创建比较安全且相互隔离的 Pod,你应该强制实施 Baseline 或 Restricted Pod 安全标准。 你可以使用 Pod 安全性准入或其他(第三方)机制来强制实施这些限制。
出于这些原因,命名空间应该用于隔离不同的信任级别或不同租户所需的资源。 遵循最小特权原则并分配最小权限集仍被认为是最佳实践, 但命名空间内的边界概念应视为比较弱。
持久卷的创建
如 PodSecurityPolicy
文档中所述,创建 PersistentVolumes 的权限可以提权访问底层主机。
如果需要访问 PersistentVolume,受信任的管理员应该创建 PersistentVolume,
受约束的用户应该使用 PersistentVolumeClaim 访问该存储。
访问 Node 的 proxy 子资源
有权访问 Node 对象的 proxy 子资源的用户有权访问 Kubelet API, 这允许在他们有权访问的节点上的所有 Pod 上执行命令。 此访问绕过审计日志记录和准入控制,因此在授予对此资源的权限前应小心。
esclate 动词
通常,RBAC 系统会阻止用户创建比他所拥有的更多权限的 ClusterRole。
而 escalate 动词是个例外。如
RBAC 文档
中所述,拥有此权限的用户可以有效地提升他们的权限。
bind 动词
与 escalate 动作类似,授予此权限的用户可以绕过 Kubernetes
对权限提升的内置保护,用户可以创建并绑定尚不具有的权限的角色。
impersonate 动词
此动词允许用户伪装并获得集群中其他用户的权限。 授予它时应小心,以确保通过其中一个伪装账号不会获得过多的权限。
CSR 和证书颁发
CSR API 允许用户拥有 create CSR 的权限和 update
certificatesigningrequests/approval 的权限,
其中签名者是 kubernetes.io/kube-apiserver-client,
通过此签名创建的客户端证书允许用户向集群进行身份验证。
这些客户端证书可以包含任意的名称,包括 Kubernetes 系统组件的副本。
这将有利于特权提级。
令牌请求
拥有 serviceaccounts/token 的 create 权限的用户可以创建
TokenRequest 来发布现有服务帐户的令牌。
控制准入 Webhook
可以控制 validatingwebhookconfigurations 或 mutatingwebhookconfigurations
的用户可以控制能读取任何允许进入集群的对象的 webhook,
并且在有变更 webhook 的情况下,还可以变更准入的对象。
Kubernetes RBAC - 拒绝服务攻击的风险
对象创建拒绝服务
有权在集群中创建对象的用户根据创建对象的大小和数量可能会创建足够大的对象, 产生拒绝服务状况,如 Kubernetes 使用的 etcd 容易受到 OOM 攻击中的讨论。 允许太不受信任或者不受信任的用户对系统进行有限的访问在多租户集群中是特别重要的。
缓解此问题的一种选择是使用资源配额以限制可以创建的对象数量。
接下来
- 了解有关 RBAC 的更多信息,请参阅 RBAC 文档。
8 - Kubernetes Secret 良好实践
在 Kubernetes 中,Secret 是这样一个对象: secret 用于存储敏感信息,如密码、OAuth 令牌和 SSH 密钥。
Secret 允许用户对如何使用敏感信息进行更多的控制,并减少信息意外暴露的风险。 默认情况下,Secret 值被编码为 base64 字符串并以非加密的形式存储,但可以配置为 静态加密(Encrypt at rest)。
Pod 可以通过多种方式引用 Secret, 例如在卷挂载中引用或作为环境变量引用。Secret 设计用于机密数据,而 ConfigMap 设计用于非机密数据。
以下良好实践适用于集群管理员和应用开发者。遵从这些指导方针有助于提高 Secret 对象中敏感信息的安全性, 还可以更有效地管理你的 Secret。
集群管理员
本节提供了集群管理员可用于提高集群中机密信息安全性的良好实践。
配置静态加密
默认情况下,Secret 对象以非加密的形式存储在 etcd 中。
你配置对在 etcd 中存储的 Secret 数据进行加密。相关的指导信息,
请参阅静态加密 Secret 数据。
配置 Secret 资源的最小特权访问
当规划诸如 Kubernetes
基于角色的访问控制 (RBAC)
这类访问控制机制时,需要注意访问 Secret 对象的以下指导信息。
你还应遵从 RBAC 良好实践中的其他指导信息。
- 组件:限制仅最高特权的系统级组件可以执行
watch或list访问。 仅在组件的正常行为需要时才授予对 Secret 的get访问权限。 - 人员:限制对 Secret 的
get、watch或list访问权限。仅允许集群管理员访问etcd。 这包括只读访问。对于更复杂的访问控制,例如使用特定注解限制对 Secret 的访问,请考虑使用第三方鉴权机制。
授予对 Secret 的 list 访问权限将意味着允许对应主体获取 Secret 的内容。
如果一个用户可以创建使用某 Secret 的 Pod,则该用户也可以看到该 Secret 的值。 即使集群策略不允许用户直接读取 Secret,同一用户也可能有权限运行 Pod 进而暴露该 Secret。 你可以检测或限制具有此访问权限的用户有意或无意地暴露 Secret 数据所造成的影响。 这里有一些建议:
- 使用生命期短暂的 Secret
- 实现对特定事件发出警报的审计规则,例如同一用户并发读取多个 Secret 时发出警报
改进 etcd 管理策略
不再使用 etcd 所使用的持久存储时,考虑擦除或粉碎这些数据。
如果存在多个 etcd 实例,则在实例之间配置加密的 SSL/TLS 通信以保护传输中的 Secret 数据。
配置对外部 Secret 的访问权限
你可以使用第三方 Secret 存储提供商将机密数据保存在你的集群之外,然后配置 Pod 访问该信息。 Kubernetes Secret 存储 CSI 驱动是一个 DaemonSet, 它允许 kubelet 从外部存储中检索 Secret,并将 Secret 作为卷挂载到特定的、你授权访问数据的 Pod。
有关支持的提供商列表,请参阅 Secret 存储 CSI 驱动的提供商。
开发者
本节为开发者提供了构建和部署 Kubernetes 资源时用于改进机密数据安全性的良好实践。
限制特定容器集合才能访问 Secret
如果你在一个 Pod 中定义了多个容器,且仅其中一个容器需要访问 Secret,则可以定义卷挂载或环境变量配置, 这样其他容器就不会有访问该 Secret 的权限。
读取后保护 Secret 数据
应用程序从一个环境变量或一个卷读取机密信息的值后仍然需要保护这些值。 例如,你的应用程序必须避免以明文记录 Secret 数据,还必须避免将这些数据传输给不受信任的一方。
避免共享 Secret 清单
如果你通过清单(Manifest)配置 Secret, 同时将该 Secret 数据编码为 base64, 那么共享此文件或将其检入一个源代码仓库就意味着有权读取该清单的所有人都能使用该 Secret。
Base64 编码 不是 一种加密方法,它没有为纯文本提供额外的保密机制。
9 - 多租户
此页面概述了集群多租户的可用配置选项和最佳实践。
共享集群可以节省成本并简化管理。 然而,共享集群也带来了诸如安全性、公平性和管理嘈杂邻居等挑战。
集群可以通过多种方式共享。在某些情况下,不同的应用可能会在同一个集群中运行。 在其他情况下,同一应用的多个实例可能在同一个集群中运行,每个实例对应一个最终用户。 所有这些类型的共享经常使用一个总括术语 多租户(Multi-Tenancy) 来表述。
虽然 Kubernetes 没有最终用户或租户的一阶概念, 它还是提供了几个特性来帮助管理不同的租户需求。下面将对此进行讨论。
用例
确定如何共享集群的第一步是理解用例,以便你可以评估可用的模式和工具。 一般来说,Kubernetes 集群中的多租户分为两大类,但也可以有许多变体和混合。
多团队
多租户的一种常见形式是在组织内的多个团队之间共享一个集群,每个团队可以操作一个或多个工作负载。 这些工作负载经常需要相互通信,并与位于相同或不同集群上的其他工作负载进行通信。
在这一场景中,团队成员通常可以通过类似 kubectl 等工具直接访问 Kubernetes 资源,
或者通过 GitOps 控制器或其他类型的自动化发布工具间接访问 Kubernetes 资源。
不同团队的成员之间通常存在某种程度的信任,
但 RBAC、配额和网络策略等 Kubernetes 策略对于安全、公平地共享集群至关重要。
多客户
多租户的另一种主要形式通常涉及为客户运行多个工作负载实例的软件即服务 (SaaS) 供应商。
这种业务模型与其部署风格之间的相关非常密切,以至于许多人称之为 “SaaS 租户”。
但是,更好的术语可能是“多客户租户(Multi-Customer Tenancy)”,因为 SaaS 供应商也可以使用其他部署模型,
并且这种部署模型也可以在 SaaS 之外使用。
在这种情况下,客户无权访问集群; 从他们的角度来看,Kubernetes 是不可见的,仅由供应商用于管理工作负载。 成本优化通常是一个关键问题,Kubernetes 策略用于确保工作负载彼此高度隔离。
术语
租户
在讨论 Kubernetes 中的多租户时,“租户”没有单一的定义。 相反,租户的定义将根据讨论的是多团队还是多客户租户而有所不同。
在多团队使用中,租户通常是一个团队, 每个团队通常部署少量工作负载,这些工作负载会随着服务的复杂性而发生规模伸缩。 然而,“团队”的定义本身可能是模糊的, 因为团队可能被组织成更高级别的部门或细分为更小的团队。
相反,如果每个团队为每个新客户部署专用的工作负载,那么他们使用的是多客户租户模型。 在这种情况下,“租户”只是共享单个工作负载的一组用户。 这种租户可能大到整个公司,也可能小到该公司的一个团队。
在许多情况下,同一组织可能在不同的上下文中使用“租户”的两种定义。 例如,一个平台团队可能向多个内部“客户”提供安全工具和数据库等共享服务, 而 SaaS 供应商也可能让多个团队共享一个开发集群。 最后,混合架构也是可能的, 例如,某 SaaS 提供商为每个客户的敏感数据提供独立的工作负载,同时提供多租户共享的服务。
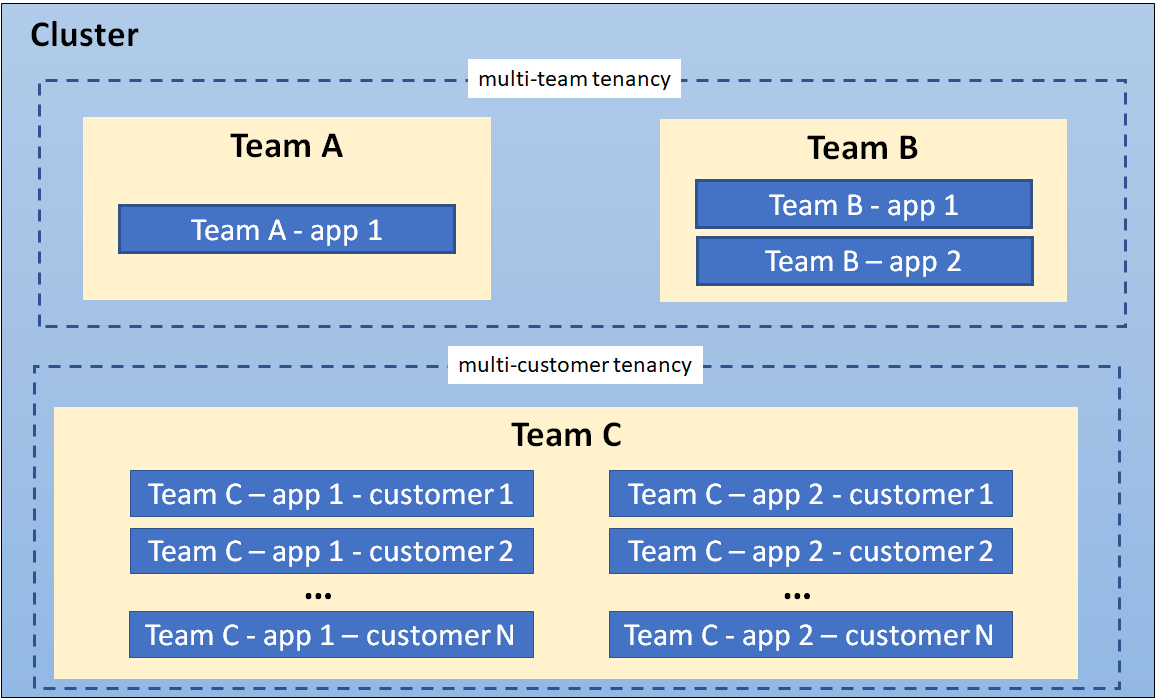
展示共存租户模型的集群
隔离
使用 Kubernetes 设计和构建多租户解决方案有多种方法。 每种方法都有自己的一组权衡,这些权衡会影响隔离级别、实现工作量、操作复杂性和服务成本。
Kubernetes 集群由运行 Kubernetes 软件的控制平面和由工作节点组成的数据平面组成, 租户工作负载作为 Pod 在工作节点上执行。 租户隔离可以根据组织要求应用于控制平面和数据平面。
所提供的隔离级别有时会使用一些术语来描述,例如 “硬性(Hard)” 多租户意味着强隔离, 而 “柔性(Soft)” 多租户意味着较弱的隔离。 特别是,“硬性”多租户通常用于描述租户彼此不信任的情况, 并且大多是从安全和资源共享的角度(例如,防范数据泄露或 DoS 攻击等)。 由于数据平面通常具有更大的攻击面,“硬性”多租户通常需要额外注意隔离数据平面, 尽管控制平面隔离也很关键。
但是,“硬性”和“柔性”这两个术语常常令人困惑,因为没有一种定义能够适用于所有用户。 相反,依据“硬度(Hardness)”或“柔度(Softness)”所定义的广泛谱系则更容易理解, 根据你的需求,可以使用许多不同的技术在集群中维护不同类型的隔离。
在更极端的情况下,彻底放弃所有集群级别的共享并为每个租户分配其专用集群可能更容易或有必要, 如果认为虚拟机所提供的安全边界还不够,甚至可以在专用硬件上运行。 对于托管的 Kubernetes 集群而言,这种方案可能更容易, 其中创建和操作集群的开销至少在一定程度上由云提供商承担。 必须根据管理多个集群的成本和复杂性来评估更强的租户隔离的好处。 Multi-Cluster SIG 负责解决这些类型的用例。
本页的其余部分重点介绍用于共享 Kubernetes 集群的隔离技术。 但是,即使你正在考虑使用专用集群,查看这些建议也可能很有价值, 因为如果你的需求或功能发生变化,它可以让你在未来比较灵活地切换到共享集群。
控制面隔离
控制平面隔离确保不同租户无法访问或影响彼此的 Kubernetes API 资源。
命名空间
在 Kubernetes 中, 命名空间提供了一种在单个集群中隔离 API 资源组的机制。 这种隔离有两个关键维度:
- 一个命名空间中的对象名称可以与其他命名空间中的名称重叠,类似于文件夹中的文件。 这允许租户命名他们的资源,而无需考虑其他租户在做什么。
- 许多 Kubernetes 安全策略的作用域是命名空间。 例如,RBAC Role 和 NetworkPolicy 是命名空间作用域的资源。 使用 RBAC,可以将用户和服务帐户限制在一个命名空间中。
在多租户环境中,命名空间有助于将租户的工作负载划分到各不相同的逻辑管理单元中。 事实上,一种常见的做法是将每个工作负载隔离在自己的命名空间中, 即使多个工作负载由同一个租户操作。 这可确保每个工作负载都有自己的身份,并且可以使用适当的安全策略进行配置。
命名空间隔离模型需要配置其他几个 Kubernetes 资源、网络插件, 并遵守安全最佳实践以正确隔离租户工作负载。 这些考虑将在下面讨论。
访问控制
控制平面最重要的隔离类型是授权。如果各个团队或其工作负载可以访问或修改彼此的 API 资源, 他们可以更改或禁用所有其他类型的策略,从而取消这些策略可能提供的任何保护。 因此,确保每个租户只对他们需要的命名空间有适当的访问权, 而不是更多,这一点至关重要。这被称为“最小特权原则(Principle of Least Privileges)”。
基于角色的访问控制 (RBAC) 通常用于在 Kubernetes 控制平面中对用户和工作负载(服务帐户)强制执行鉴权。 角色 和角色绑定是两种 Kubernetes 对象,用来在命名空间级别对应用实施访问控制; 对集群级别的对象访问鉴权也有类似的对象,不过这些对象对于多租户集群不太有用。
在多团队环境中,必须使用 RBAC 来限制租户只能访问合适的命名空间, 并确保集群范围的资源只能由集群管理员等特权用户访问或修改。
如果一个策略最终授予用户的权限比他们所需要的还多, 这可能是一个信号,表明包含受影响资源的命名空间应该被重构为更细粒度的命名空间。 命名空间管理工具可以通过将通用 RBAC 策略应用于不同的命名空间来简化这些细粒度命名空间的管理, 同时在必要时仍允许细粒度策略。
配额
Kubernetes 工作负载消耗节点资源,例如 CPU 和内存。在多租户环境中, 你可以使用资源配额来管理租户工作负载的资源使用情况。 对于多团队场景,各个租户可以访问 Kubernetes API,你可以使用资源配额来限制租户可以创建的 API 资源的数量 (例如:Pod 的数量,或 ConfigMap 的数量)。 对对象计数的限制确保了公平性,并有助于避免嘈杂邻居问题影响共享控制平面的其他租户。
资源配额是命名空间作用域的对象。 通过将租户映射到命名空间, 集群管理员可以使用配额来确保租户不能垄断集群的资源或压垮控制平面。 命名空间管理工具简化了配额的管理。 此外,虽然 Kubernetes 配额仅针对单个命名空间, 但一些命名空间管理工具允许多个命名空间组共享配额, 与内置配额相比,降低了管理员的工作量,同时为其提供了更大的灵活性。
配额可防止单个租户所消耗的资源超过其被分配的份额,从而最大限度地减少嘈杂邻居问题, 即一个租户对其他租户工作负载的性能产生负面影响。
当你对命名空间应用配额时, Kubernetes 要求你还为每个容器指定资源请求和限制。 限制是容器可以消耗的资源量的上限。 根据资源类型,尝试使用超出配置限制的资源的容器将被限制或终止。 当资源请求设置为低于限制时, 每个容器所请求的数量都可以得到保证,但可能仍然存在跨工作负载的一些潜在影响。
配额不能针对所共享的所有资源(例如网络流量)提供保护。 节点隔离(如下所述)可能是解决此问题的更好方法。
数据平面隔离
数据平面隔离确保不同租户的 Pod 和工作负载之间被充分隔离。
网络隔离
默认情况下,Kubernetes 集群中的所有 Pod 都可以相互通信,并且所有网络流量都是未加密的。 这可能导致安全漏洞,导致流量被意外或恶意发送到非预期目的地, 或被受感染节点上的工作负载拦截。
Pod 之间的通信可以使用网络策略来控制, 它使用命名空间标签或 IP 地址范围来限制 Pod 之间的通信。 在需要租户之间严格网络隔离的多租户环境中, 建议从拒绝 Pod 之间通信的默认策略入手, 然后添加一条允许所有 Pod 查询 DNS 服务器以进行名称解析的规则。 有了这样的默认策略之后,你就可以开始添加允许在命名空间内进行通信的更多规则。 另外建议不要在网络策略定义中对 namespaceSelector 字段使用空标签选择算符 “{}”, 以防需要允许在命名空间之间传输流量。 该方案可根据需要进一步细化。 请注意,这仅适用于单个控制平面内的 Pod; 属于不同虚拟控制平面的 Pod 不能通过 Kubernetes 网络相互通信。
命名空间管理工具可以简化默认或通用网络策略的创建。 此外,其中一些工具允许你在整个集群中强制实施一组一致的命名空间标签, 确保它们是你策略的可信基础。
网络策略需要一个支持网络策略实现的 CNI 插件。 否则,NetworkPolicy 资源将被忽略。
服务网格可以提供更高级的网络隔离, 除了命名空间之外,它还提供基于工作负载身份的 OSI 第 7 层策略。 这些更高层次的策略可以更轻松地管理基于命名空间的多租户, 尤其是存在多个命名空间专用于某一个租户时。 服务网格还经常使用双向 TLS 提供加密能力, 即使在存在受损节点的情况下也能保护你的数据, 并且可以跨专用或虚拟集群工作。 但是,它们的管理可能要复杂得多,并且可能并不适合所有用户。
存储隔离
Kubernetes 提供了若干类型的卷,可以用作工作负载的持久存储。 为了安全和数据隔离,建议使用动态卷制备, 并且应避免使用节点资源的卷类型。
存储类(StorageClass)允许你根据服务质量级别、 备份策略或由集群管理员确定的自定义策略描述集群提供的自定义存储“类”。
Pod 可以使用持久卷申领(PersistentVolumeClaim)请求存储。 PersistentVolumeClaim 是一种命名空间作用域的资源, 它可以隔离存储系统的不同部分,并将隔离出来的存储提供给共享 Kubernetes 集群中的租户专用。 但是,重要的是要注意 PersistentVolume 是集群作用域的资源, 并且其生命周期独立于工作负载和命名空间的生命周期。
例如,你可以为每个租户配置一个单独的 StorageClass,并使用它来加强隔离。 如果一个 StorageClass 是共享的,你应该设置一个回收策略 以确保 PersistentVolume 不能在不同的命名空间中重复使用。
沙箱容器
Kubernetes Pod 由在工作节点上执行的一个或多个容器组成。 容器利用操作系统级别的虚拟化, 因此提供的隔离边界比使用基于硬件虚拟化的虚拟机弱一些。
在共享环境中,攻击者可以利用应用和系统层中未修补的漏洞实现容器逃逸和远程代码执行, 从而允许访问主机资源。 在某些应用中,例如内容管理系统(CMS), 客户可能被授权上传和执行非受信的脚本或代码。 无论哪种情况,都需要使用强隔离进一步隔离和保护工作负载的机制。
沙箱提供了一种在共享集群中隔离运行中的工作负载的方法。 它通常涉及在单独的执行环境(例如虚拟机或用户空间内核)中运行每个 Pod。 当你运行不受信任的代码时(假定工作负载是恶意的),通常建议使用沙箱, 这种隔离是必要的,部分原因是由于容器是在共享内核上运行的进程。 它们从底层主机挂载像 /sys 和 /proc 这样的文件系统, 这使得它们不如在具有自己内核的虚拟机上运行的应用安全。 虽然 seccomp、AppArmor 和 SELinux 等控件可用于加强容器的安全性, 但很难将一套通用规则应用于在共享集群中运行的所有工作负载。 在沙箱环境中运行工作负载有助于将主机隔离开来,不受容器逃逸影响, 在容器逃逸场景中,攻击者会利用漏洞来访问主机系统以及在该主机上运行的所有进程/文件。
虚拟机和用户空间内核是两种流行的沙箱方法。 可以使用以下沙箱实现:
- gVisor 拦截来自容器的系统调用,并通过用户空间内核运行它们, 用户空间内核采用 Go 编写,对底层主机的访问是受限的
- Kata Containers 是符合 OCI 的运行时,允许你在 VM 中运行容器。 Kata 中提供的硬件虚拟化为运行不受信任代码的容器提供了额外的安全层。
节点隔离
节点隔离是另一种可用于将租户工作负载相互隔离的技术。 通过节点隔离,一组节点专用于运行来自特定租户的 Pod,并且禁止混合不同租户 Pod 集合。 这种配置减少了嘈杂的租户问题,因为在一个节点上运行的所有 Pod 都将属于一个租户。 节点隔离的信息泄露风险略低, 因为成功实现容器逃逸的攻击者也只能访问挂载在该节点上的容器和卷。
尽管来自不同租户的工作负载在不同的节点上运行, 仍然很重要的是要注意 kubelet 和 (除非使用虚拟控制平面)API 服务仍然是共享服务。 熟练的攻击者可以使用分配给 kubelet 或节点上运行的其他 Pod 的权限在集群内横向移动并获得对其他节点上运行的租户工作负载的访问权限。 如果这是一个主要问题,请考虑实施补偿控制, 例如使用 seccomp、AppArmor 或 SELinux,或者探索使用沙箱容器,或者为每个租户创建单独的集群。
从计费的角度来看,节点隔离比沙箱容器更容易理解, 因为你可以按节点而不是按 Pod 收费。 它的兼容性和性能问题也较少,而且可能比沙箱容器更容易实现。 例如,可以为每个租户的节点配置污点, 以便只有具有相应容忍度的 Pod 才能在其上运行。 然后可以使用变更性质的 Webhook 自动向部署到租户命名空间中的 Pod 添加容忍度和节点亲和性, 以便它们在为该租户指定的一组特定节点上运行。
节点隔离可以使用将 Pod 指派给节点或 Virtual Kubelet 来实现。
额外的注意事项
本节讨论与多租户相关的其他 Kubernetes 结构和模式。
API 优先级和公平性
API 优先级和公平性是 Kubernetes 的一个特性, 允许你为集群中运行的某些 Pod 赋予优先级。 当应用调用 Kubernetes API 时,API 服务器会评估分配给 Pod 的优先级。 来自具有较高优先级的 Pod 的调用会在具有较低优先级的 Pod 的调用之前完成。 当争用很激烈时,较低优先级的调用可以排队,直到服务器不那么忙,或者你可以拒绝请求。
使用 API 优先级和公平性在 SaaS 环境中并不常见, 除非你允许客户运行与 Kubernetes API 接口的应用,例如控制器。
服务质量 (QoS)
当你运行 SaaS 应用时, 你可能希望能够为不同的租户提供不同的服务质量 (QoS) 层级。 例如,你可能拥有具有性能保证和功能较差的免费增值服务, 以及具有一定性能保证的收费服务层。 幸运的是,有几个 Kubernetes 结构可以帮助你在共享集群中完成此任务, 包括网络 QoS、存储类以及 Pod 优先级和抢占。 这些都是为了给租户提供他们所支付的服务质量。 让我们从网络 QoS 开始。
通常,节点上的所有 Pod 共享一个网络接口。 如果没有网络 QoS,一些 Pod 可能会以牺牲其他 Pod 为代价不公平地消耗可用带宽。 Kubernetes 带宽插件为网络创建 扩展资源, 以允许你使用 Kubernetes 的 resources 结构,即 requests 和 limits 设置。 通过使用 Linux tc 队列将速率限制应用于 Pod。 请注意,根据支持流量整形文档, 该插件被认为是实验性的,在生产环境中使用之前应该进行彻底的测试。
对于存储 QoS,你可能希望创建具有不同性能特征的不同存储类或配置文件。 每个存储配置文件可以与不同的服务层相关联,该服务层针对 IO、冗余或吞吐量等不同的工作负载进行优化。 可能需要额外的逻辑来允许租户将适当的存储配置文件与其工作负载相关联。
最后,还有 Pod 优先级和抢占, 你可以在其中为 Pod 分配优先级值。 在调度 Pod 时,当没有足够的资源来调度分配了较高优先级的 Pod 时, 调度程序将尝试驱逐具有较低优先级的 Pod。 如果你有一个用例,其中租户在共享集群中具有不同的服务层,例如免费和付费, 你可能希望使用此功能为某些层级提供更高的优先级。
DNS
Kubernetes 集群包括一个域名系统(DNS)服务, 可为所有服务和 Pod 提供从名称到 IP 地址的转换。 默认情况下,Kubernetes DNS 服务允许在集群中的所有命名空间中进行查找。
在多租户环境中,租户可以访问 Pod 和其他 Kubernetes 资源, 或者在需要更强隔离的情况下,可能需要阻止 Pod 在其他名称空间中查找服务。 你可以通过为 DNS 服务配置安全规则来限制跨命名空间的 DNS 查找。 例如,CoreDNS(Kubernetes 的默认 DNS 服务)可以利用 Kubernetes 元数据来限制对命名空间内的 Pod 和服务的查询。 有关更多信息,请阅读 CoreDNS 文档中配置此功能的 示例。
当使用各租户独立虚拟控制面模型时, 必须为每个租户配置 DNS 服务或必须使用多租户 DNS 服务。参见一个 CoreDNS 的定制版本支持多租户的示例。
Operators
Operator 模式是管理应用的 Kubernetes 控制器。 Operator 可以简化应用的多个实例的管理,例如数据库服务, 这使它们成为多消费者 (SaaS) 多租户用例中的通用构建块。
在多租户环境中使用 Operators 应遵循一套更严格的准则。具体而言,Operator 应:
- 支持在不同的租户命名空间内创建资源,而不仅仅是在部署 Operator 的命名空间内。
- 确保 Pod 配置了资源请求和限制,以确保调度和公平。
- 支持节点隔离、沙箱容器等数据平面隔离技术的 Pod 配置。
实现
为多租户共享 Kubernetes 集群有两种主要方法: 使用命名空间(即每个租户独立的命名空间) 或虚拟化控制平面(即每个租户独立的虚拟控制平面)。
在这两种情况下,还建议对数据平面隔离和其他考虑事项,如 API 优先级和公平性,进行管理。
Kubernetes 很好地支持命名空间隔离,其资源开销可以忽略不计,并提供了允许租户适当交互的机制, 例如允许服务之间的通信。 但是,它可能很难配置,而且不适用于非命名空间作用域的 Kubernetes 资源,例如自定义资源定义、存储类和 Webhook 等。
控制平面虚拟化允许以更高的资源使用率和更困难的跨租户共享为代价隔离非命名空间作用域的资源。 当命名空间隔离不足但不希望使用专用集群时,这是一个不错的选择, 因为维护专用集群的成本很高(尤其是本地集群), 或者由于专用集群的额外开销较高且缺乏资源共享。 但是,即使在虚拟化控制平面中,你也可能会看到使用命名空间的好处。
以下各节将更详细地讨论这两个选项:
每个租户独立的命名空间
如前所述,你应该考虑将每个工作负载隔离在其自己的命名空间中, 即使你使用的是专用集群或虚拟化控制平面。 这可确保每个工作负载只能访问其自己的资源,例如 ConfigMap 和 Secret, 并允许你为每个工作负载定制专用的安全策略。 此外,最佳实践是为整个集群中的每个命名空间名称提供唯一的名称(即,即使它们位于单独的集群中), 因为这使你将来可以灵活地在专用集群和共享集群之间切换, 或者使用多集群工具,例如服务网格。
相反,在租户级别分配命名空间也有优势, 而不仅仅是工作负载级别, 因为通常有一些策略适用于单个租户拥有的所有工作负载。 然而,这种方案也有自己的问题。 首先,这使得为各个工作负载定制策略变得困难或不可能, 其次,确定应该赋予命名空间的单一级别的 “租户” 可能很困难。 例如,一个组织可能有部门、团队和子团队 - 哪些应该分配一个命名空间?
为了解决这个问题,Kubernetes 提供了 Hierarchical Namespace Controller (HNC), 它允许你将多个命名空间组织成层次结构,并在它们之间共享某些策略和资源。 它还可以帮助你管理命名空间标签、命名空间生命周期和委托管理, 并在相关命名空间之间共享资源配额。 这些功能在多团队和多客户场景中都很有用。
下面列出了提供类似功能并有助于管理命名空间资源的其他项目:
多团队租户
多客户租户
策略引擎
策略引擎提供了验证和生成租户配置的特性:
每个租户独立的虚拟控制面
控制面隔离的另一种形式是使用 Kubernetes 扩展为每个租户提供一个虚拟控制面, 以实现集群范围内 API 资源的分段。 数据平面隔离技术可以与此模型一起使用, 以安全地跨多个租户管理工作节点。
基于虚拟控制面的多租户模型通过为每个租户提供专用控制面组件来扩展基于命名空间的多租户, 从而完全控制集群范围的资源和附加服务。 工作节点在所有租户之间共享,并由租户通常无法访问的 Kubernetes 集群管理。 该集群通常被称为 超集群(Super-Cluster)(或有时称为 host-cluster)。 由于租户的控制面不直接与底层计算资源相关联,因此它被称为虚拟控制平面。
虚拟控制面通常由 Kubernetes API 服务器、控制器管理器和 etcd 数据存储组成。 它通过元数据同步控制器与超集群交互, 该控制器跨租户控制面和超集群控制面对变化进行协调。
通过使用每个租户单独的专用控制面,可以解决由于所有租户共享一个 API 服务器而导致的大部分隔离问题。 例如,控制平面中的嘈杂邻居、策略错误配置导致的不可控爆炸半径以及如 Webhook 和 CRD 等集群范围对象之间的冲突。 因此,虚拟控制平面模型特别适用于每个租户都需要访问 Kubernetes API 服务器并期望具有完整集群可管理性的情况。
改进的隔离是以每个租户运行和维护一个单独的虚拟控制平面为代价的。 此外,租户层面的控制面不能解决数据面的隔离问题, 例如节点级的嘈杂邻居或安全威胁。这些仍然必须单独解决。
Kubernetes Cluster API - Nested (CAPN) 项目提供了虚拟控制平面的实现。
其他实现
10 - Kubernetes API 服务器旁路风险
Kubernetes API 服务器是外部(用户和服务)与集群交互的主要入口。
作为此角色的一部分,API 服务器有几个关键的内置安全控制, 例如审计日志和准入控制器。 但是,有一些方法可以绕过这些安全控制从而修改集群的配置或内容。
本页描述了绕过 Kubernetes API 服务器中内置安全控制的几种方式, 以便集群运维人员和安全架构师可以确保这些绕过方式被适当地限制。
静态 Pod
每个节点上的 kubelet 会加载并直接管理集群中存储在指定目录中或从特定 URL 获取的静态 Pod 清单。 API 服务器不管理这些静态 Pod。对该位置具有写入权限的攻击者可以修改从该位置加载的静态 Pod 的配置,或引入新的静态 Pod。
静态 Pod 被限制访问 Kubernetes API 中的其他对象。例如,你不能将静态 Pod 配置为从集群挂载 Secret。
但是,这些 Pod 可以执行其他安全敏感的操作,例如挂载来自下层节点的 hostPath 卷。
默认情况下,kubelet 会创建一个镜像 Pod(Mirror Pod), 以便静态 Pod 在 Kubernetes API 中可见。但是,如果攻击者在创建 Pod 时使用了无效的名字空间名称, 则该 Pod 将在 Kubernetes API 中不可见,只能通过对受影响主机有访问权限的工具发现。
如果静态 Pod 无法通过准入控制,kubelet 不会将 Pod 注册到 API 服务器。但该 Pod 仍然在节点上运行。 有关更多信息,请参阅 kubeadm issue #1541。
缓解措施
- 仅在节点需要时启用 kubelet 静态 Pod 清单功能。
- 如果节点使用静态 Pod 功能,请将对静态 Pod 清单目录或 URL 的文件系统的访问权限限制为需要访问的用户。
- 限制对 kubelet 配置参数和文件的访问,以防止攻击者设置静态 Pod 路径或 URL。
- 定期审计并集中报告所有对托管静态 Pod 清单和 kubelet 配置文件的目录或 Web 存储位置的访问。
kubelet API
kubelet 提供了一个 HTTP API,通常暴露在集群工作节点上的 TCP 端口 10250 上。 在某些 Kubernetes 发行版中,API 也可能暴露在控制平面节点上。 对 API 的直接访问允许公开有关运行在节点上的 Pod、这些 Pod 的日志以及在节点上运行的每个容器中执行命令的信息。
当 Kubernetes 集群用户具有对 Node 对象子资源 RBAC 访问权限时,该访问权限可用作与 kubelet API 交互的授权。
实际的访问权限取决于授予了哪些子资源访问权限,详见
kubelet 鉴权。
对 kubelet API 的直接访问不受准入控制影响,也不会被 Kubernetes 审计日志记录。 能直接访问此 API 的攻击者可能会绕过能检测或防止某些操作的控制机制。
kubelet API 可以配置为以多种方式验证请求。
默认情况下,kubelet 的配置允许匿名访问。大多数 Kubernetes 提供商将默认值更改为使用 Webhook 和证书身份认证。
这使得控制平面能够确保调用者访问 Node API 资源或子资源是经过授权的。但控制平面不能确保默认的匿名访问也是如此。
缓解措施
- 使用 RBAC 等机制限制对
NodeAPI 对象的子资源的访问。 只在有需要时才授予此访问权限,例如监控服务。 - 限制对 kubelet 端口的访问。只允许指定和受信任的 IP 地址段访问该端口。
- 确保将 kubelet 身份验证设置为 Webhook 或证书模式。
- 确保集群上未启用不作身份认证的“只读” Kubelet 端口。
etcd API
Kubernetes 集群使用 etcd 作为数据存储。etcd 服务监听 TCP 端口 2379。
只有 Kubernetes API 服务器和你所使用的备份工具需要访问此存储。对该 API 的直接访问允许公开或修改集群中保存的数据。
对 etcd API 的访问通常通过客户端证书身份认证来管理。 由 etcd 信任的证书颁发机构所颁发的任何证书都可以完全访问 etcd 中存储的数据。
对 etcd 的直接访问不受 Kubernetes 准入控制的影响,也不会被 Kubernetes 审计日志记录。 具有对 API 服务器的 etcd 客户端证书私钥的读取访问权限(或可以创建一个新的受信任的客户端证书) 的攻击者可以通过访问集群 Secret 或修改访问规则来获得集群管理员权限。 即使不提升其 Kubernetes RBAC 权限,可以修改 etcd 的攻击者也可以在集群内检索所有 API 对象或创建新的工作负载。
许多 Kubernetes 提供商配置 etcd 为使用双向 TLS(客户端和服务器都验证彼此的证书以进行身份验证)。 尽管存在该特性,但目前还没有被广泛接受的 etcd API 鉴权实现。 由于缺少鉴权模型,任何具有对 etcd 的客户端访问权限的证书都可以用于获得对 etcd 的完全访问权限。 通常,仅用于健康检查的 etcd 客户端证书也可以授予完全读写访问权限。
缓解措施
- 确保 etcd 所信任的证书颁发机构仅用于该服务的身份认证。
- 控制对 etcd 服务器证书的私钥以及 API 服务器的客户端证书和密钥的访问。
- 考虑在网络层面限制对 etcd 端口的访问,仅允许来自特定和受信任的 IP 地址段的访问。
容器运行时套接字
在 Kubernetes 集群中的每个节点上,与容器交互的访问都由容器运行时控制。 通常,容器运行时会公开一个 kubelet 可以访问的 UNIX 套接字。 具有此套接字访问权限的攻击者可以启动新容器或与正在运行的容器进行交互。
在集群层面,这种访问造成的影响取决于在受威胁节点上运行的容器是否可以访问 Secret 或其他机密数据, 攻击者可以使用这些机密数据将权限提升到其他工作节点或控制平面组件。
缓解措施
- 确保严格控制对容器运行时套接字所在的文件系统访问。如果可能,限制为仅
root用户可访问。 - 使用 Linux 内核命名空间等机制将 kubelet 与节点上运行的其他组件隔离。
- 确保限制或禁止使用包含容器运行时套接字的
hostPath挂载, 无论是直接挂载还是通过挂载父目录挂载。此外,hostPath挂载必须设置为只读,以降低攻击者绕过目录限制的风险。 - 限制用户对节点的访问,特别是限制超级用户对节点的访问。
11 - 安全检查清单
本清单旨在提供一个基本的指导列表,其中包含链接,指向各个主题的更为全面的文档。 此清单不求详尽无遗,是预计会不断演化的。
关于如何阅读和使用本文档:
- 主题的顺序并不代表优先级的顺序。
- 在每章节的列表下面的段落中,都详细列举了一些检查清项目。
单靠检查清单是不够的,无法获得良好的安全态势。 实现良好的安全态势需要持续的关注和改进,实现安全上有备无患的目标道路漫长,清单可作为征程上的第一步。 对于你的特定安全需求,此清单中的某些建议可能过于严格或过于宽松。 由于 Kubernetes 的安全性并不是“一刀切”的,因此针对每一类检查清单项目都应该做价值评估。
认证和鉴权
- 在启动后
system:masters组不用于用户或组件的身份验证。 - kube-controller-manager 运行时要启用
--use-service-account-credentials参数。 - 根证书要受到保护(或离线 CA,或一个具有有效访问控制的托管型在线 CA)。
- 中级证书和叶子证书的有效期不要超过未来 3 年。
- 存在定期访问审查的流程,审查间隔不要超过 24 个月。
- 遵循基于角色的访问控制良好实践,以获得与身份验证和授权相关的指导。
在启动后,用户和组件都不应以 system:masters 身份向 Kubernetes API 进行身份验证。
同样,应避免将任何 kube-controller-manager 以 system:masters 运行。
事实上,system:masters 应该只用作一个例外机制,而不是管理员用户。
网络安全
- 使用的 CNI 插件可支持网络策略。
- 对集群中的所有工作负载应用入站和出站的网络策略。
- 落实每个名称空间内的默认网络策略,覆盖所有 Pod,拒绝一切访问。
- 如果合适,使用服务网格来加密集群内的所有通信。
- 不在互联网上公开 Kubernetes API、kubelet API 和 etcd。
- 过滤工作负载对云元数据 API 的访问。
- 限制使用 LoadBalancer 和 ExternalIP。
许多容器网络接口(Container Network Interface,CNI)插件提供了限制 Pod 可能与之通信的网络资源的功能。 这种限制通常通过网络策略来完成, 网络策略提供了一种名称空间作用域的资源来定义规则。 在每个名称空间中,默认的网络策略会阻塞所有的出入站流量,并选择所有 Pod, 采用允许列表的方法很有用,可以确保不遗漏任何工作负载。
并非所有 CNI 插件都在传输过程中提供加密。 如果所选的插件缺少此功能,一种替代方案是可以使用服务网格来提供该功能。
控制平面的 etcd 数据存储应该实施访问限制控制,并且不要在互联网上公开。 此外,应使用双向 TLS(mTLS)与其进行安全通信。 用在这里的证书机构应该仅用于 etcd。
应该限制外部互联网对 Kubernetes API 服务器未公开的 API 的访问。 请小心,因为许多托管的 Kubernetes 发行版在默认情况下公开了 API 服务器。 当然,你可以使用堡垒机访问服务器。
对 kubelet API 的访问应该受到限制,
并且不公开,当没有使用 --config 参数来设置配置文件时,默认的身份验证和鉴权设置是过于宽松的。
如果使用云服务供应商托管的 Kubernetes,在没有明确需要的情况下,
也应该限制或阻止从 Pod 对云元数据 API 169.254.169.254 的访问,因为这可能泄露信息。
关于限制使用 LoadBalancer 和 ExternalIP 请参阅 CVE-2020-8554:中间人使用 LoadBalancer 或 ExternalIP 和 DenyServiceExternalIPs 准入控制器获取更多信息。
Pod 安全
- 仅在必要时才授予
create、update、patch、delete工作负载的 RBAC 权限。 - 对所有名字空间实施适当的 Pod 安全标准策略,并强制执行。
- 为工作负载设置内存限制值,并确保限制值等于或者不高于请求值。
- 对敏感工作负载可以设置 CPU 限制。
- 对于支持 Seccomp 的节点,可以为程序启用合适的系统调用配置文件。
- 对于支持 AppArmor 或 SELinux 的系统,可以为程序启用合适的配置文件。
RBAC 的授权是至关重要的,
但不能在足够细的粒度上对 Pod 的资源进行授权,
也不足以对管理 Pod 的任何资源进行授权。
唯一的粒度是资源本身上的 API 动作,例如,对 Pod 的 create。
在未指定额外许可的情况下,创建这些资源的权限允许直接不受限制地访问集群的可调度节点。
Pod 安全性标准定义了三种不同的策略:
特权策略(Privileged)、基线策略(Baseline)和限制策略(Restricted),它们限制了 PodSpec 中关于安全的字段的设置。
这些标准可以通过默认启用的新的
Pod 安全性准入或第三方准入 Webhook 在名称空间级别强制执行。
请注意,与它所取代的、已被删除的 PodSecurityPolicy 准入机制相反,
Pod 安全性准入可以轻松地与准入 Webhook 和外部服务相结合使用。
restricted Pod 安全准入策略是 Pod 安全性标准集中最严格的策略,
可以在多种种模式下运行,
根据最佳安全实践,逐步地采用 warn、audit 或者 enforce
模式以应用最合适的安全上下文(Security Context)。
尽管如此,对于特定的用例,应该单独审查 Pod 的安全上下文,
以限制 Pod 在预定义的安全性标准之上可能具有的特权和访问权限。
有关 Pod 安全性的实践教程, 请参阅博文 Kubernetes 1.23:Pod 安全性升级到 Beta。
为了限制一个 Pod 可以使用的内存和 CPU 资源, 应该设置 Pod 在节点上可消费的内存和 CPU 限制, 从而防止来自恶意的或已被攻破的工作负载的潜在 DoS 攻击。这种策略可以由准入控制器强制执行。 请注意,CPU 限制设置可能会影响 CPU 用量,从而可能会对自动扩缩功能或效率产生意外的影响, 换言之,系统会在可用的 CPU 资源下最大限度地运行进程。
内存限制高于请求的,可能会使整个节点面临 OOM 问题。
启用 Seccomp
Seccomp 通过减少容器内对 Linux 内核的系统调用(System Call)以缩小攻击面,从而提高工作负载的安全性。 Seccomp 过滤器模式借助 BPF 创建了配置文件(Profile),文件中设置对具体系统调用的允许或拒绝, 可以针对单个工作负载上启用这类 Seccomp 配置文件。你可以阅读相应的安全教程。 此外,Kubernetes Security Profiles Operator 是一个方便在集群中管理和使用 Seccomp 的项目。
从历史背景看,请注意 Docker 自 2016 年以来一直使用默认的 Seccomp 配置文件, 仅允许来自 Docker Engine 1.10 的很小的一组系统调用, 但是,在默认情况下 Kubernetes 仍不限制工作负载。 默认的 Seccomp 配置文件也可以在 containerd 中找到。 幸运的是,Seccomp Default 可将默认的 Seccomp 配置文件用于所有工作负载, 这是一项新的 Alpha 功能,现在可以启用和测试了。
Seccomp 仅适用于 Linux 节点。
启用 AppArmor 或 SELinux
AppArmor
AppArmor 是一个 Linux 内核安全模块, 可以提供一种简单的方法来实现强制访问控制(Mandatory Access Control, MAC)并通过系统日志进行更好地审计。 要在 Kubernetes 中启用 AppArmor,至少需要 1.4 版本。 与 Seccomp 一样,AppArmor 也通过配置文件进行配置, 其中每个配置文件要么在强制(Enforcing)模式下运行,即阻止访问不允许的资源,要么在投诉(Complaining)模式下运行,只报告违规行为。 AppArmor 配置文件是通过注解的方式,以容器为粒度强制执行的,允许进程获得刚好合适的权限。
AppArmor 仅在 Linux 节点上可用,在一些 Linux 发行版中已启用。
SELinux
SELinux
也是一个 Linux 内核安全模块,可以提供支持访问控制安全策略的机制,包括强制访问控制(MAC)。
SELinux 标签可以通过 securityContext 节指配给容器或 Pod。
SELinux 仅在 Linux 节点上可用,在一些 Linux 发行版中已启用。
Pod 布局
- Pod 布局是根据应用程序的敏感级别来完成的。
- 敏感应用程序在节点上隔离运行或使用特定的沙箱运行时运行。
处于不同敏感级别的 Pod,例如,应用程序 Pod 和 Kubernetes API 服务器,应该部署到不同的节点上。 节点隔离的目的是防止应用程序容器的逃逸,进而直接访问敏感度更高的应用, 甚至轻松地改变集群工作机制。 这种隔离应该被强制执行,以防止 Pod 集合被意外部署到同一节点上。 可以通过以下功能实现:
- 节点选择器(Node Selector)
- 作为 Pod 规约的一部分来设置的键值对,指定 Pod 可部署到哪些节点。 通过 PodNodeSelector 准入控制器可以在名字空间和集群级别强制实施节点选择。
- PodTolerationRestriction
- 容忍度准入控制器, 允许管理员设置在名字空间内允许使用的容忍度。 名字空间中的 Pod 只能使用名字空间对象的注解键上所指定的容忍度,这些键提供默认和允许的容忍度集合。
- RuntimeClass
- RuntimeClass 是一个用于选择容器运行时配置的特性,容器运行时配置用于运行 Pod 中的容器, 并以性能开销为代价提供或多或少的主机隔离能力。
Secrets
- 不用 ConfigMap 保存机密数据。
- 为 Secret API 配置静态加密。
- 如果合适,可以部署和使用一种机制,负责注入保存在第三方存储中的 Secret。
- 不应该将服务账号令牌挂载到不需要它们的 Pod 中。
- 使用绑定的服务账号令牌卷, 而不要使用不会过期的令牌。
Pod 所需的秘密信息应该存储在 Kubernetes Secret 中,而不是像 ConfigMap 这样的替代品中。 存储在 etcd 中的 Secret 资源应该被静态加密。
需要 Secret 的 Pod 应该通过卷自动挂载这些信息,
最好使用 emptyDir.medium 选项存储在内存中。
该机制还可以用于从第三方存储中注入 Secret 作为卷,如 Secret Store CSI 驱动。
与通过 RBAC 来允许 Pod 服务帐户访问 Secret 相比,应该优先使用上述机制。这种机制允许将 Secret 作为环境变量或文件添加到 Pod 中。
请注意,与带访问权限控制的文件相比,由于日志的崩溃转储,以及 Linux 的环境变量的非机密性,环境变量方法可能更容易发生泄漏。
不应该将服务账号令牌挂载到不需要它们的 Pod 中。
这可以通过在服务帐号内将
automountServiceAccountToken
设置为 false 来完成整个名字空间范围的配置,
或者也可以单独在 Pod 层面定制。
对于 Kubernetes v1.22 及更高版本,
请使用绑定服务账号作为有时间限制的服务帐号凭证。
镜像
- 尽量减少容器镜像中不必要的内容。
- 容器镜像配置为以非特权用户身份运行。
- 对容器镜像的引用是通过 Sha256 摘要实现的,而不是标签(tags), 或者通过准入控制器在部署时验证镜像的数字签名来验证镜像的来源。
- 在创建和部署过程中定期扫描容器镜像,并对已知的漏洞软件进行修补。
容器镜像应该包含运行其所打包的程序所需要的最少内容。 最好,只使用程序及其依赖项,基于最小的基础镜像来构建镜像。 尤其是,在生产中使用的镜像不应包含 Shell 或调试工具, 因为可以使用临时调试容器进行故障排除。
构建镜像时使用 Dockerfile 中的 USER
指令直接开始使用非特权用户。
安全上下文(Security Context)
允许使用 runAsUser 和 runAsGroup 来指定使用特定的用户和组来启动容器镜像,
即使没有在镜像清单文件(Manifest)中指定这些配置信息。
不过,镜像层中的文件权限设置可能无法做到在不修改镜像的情况下,使用新的非特权用户来启动进程。
避免使用镜像标签来引用镜像,尤其是 latest 标签,因为标签对应的镜像可以在仓库中被轻松地修改。
首选使用完整的 Sha256 摘要,该摘要对特定镜像清单文件而言是唯一的。
可以通过 ImagePolicyWebhook
强制执行此策略。
镜像签名还可以在部署时由准入控制器自动验证,
以验证其真实性和完整性。
扫描容器镜像可以防止关键性的漏洞随着容器镜像一起被部署到集群中。 镜像扫描应在将容器镜像部署到集群之前完成,通常作为 CI/CD 流水线中的部署过程的一部分来完成。 镜像扫描的目的是获取有关容器镜像中可能存在的漏洞及其预防措施的信息, 例如使用公共漏洞评分系统 (Common Vulnerability Scoring System,CVSS)评分。 如果镜像扫描的结果与管道合性规则匹配,则只有经过正确修补的容器镜像才会最终进入生产环境。
准入控制器
- 选择启用适当的准入控制器。
- Pod 安全策略由 Pod 安全准入强制执行,或者和 Webhook 准入控制器一起强制执行。
- 保证准入链插件和 Webhook 的配置都是安全的。
准入控制器可以帮助提高集群的安全性。 然而,由于它们是对 API 服务器的扩展,其自身可能会带来风险, 所以它们应该得到适当的保护。
下面列出了一些准入控制器,可以考虑用这些控制器来增强集群和应用程序的安全状况。 列表中包括了可能在本文档其他部分曾提及的控制器。
第一组准入控制器包括默认启用的插件, 除非你知道自己在做什么,否则请考虑保持它们处于被启用的状态:
CertificateApproval- 执行额外的授权检查,以确保审批用户具有审批证书请求的权限。
CertificateSigning- 执行其他授权检查,以确保签名用户具有签名证书请求的权限。
CertificateSubjectRestriction- 拒绝将
group(或organization attribute)设置为system:masters的所有证书请求。
LimitRanger- 强制执行 LimitRange API 约束。
MutatingAdmissionWebhook- 允许通过 Webhook 使用自定义控制器,这些控制器可能会变更它所审查的请求。
PodSecurity- Pod Security Policy 的替代品,用于约束所部署 Pod 的安全上下文。
ResourceQuota- 强制执行资源配额,以防止资源被过度使用。
ValidatingAdmissionWebhook- 允许通过 Webhook 使用自定义控制器,这些控制器不变更它所审查的请求。
第二组包括默认情况下没有启用、但处于正式发布状态的插件,建议启用这些插件以改善你的安全状况:
DenyServiceExternalIPs- 拒绝使用
Service.spec.externalIPs字段,已有的 Service 不受影响,新增或者变更时不允许使用。 这是 CVE-2020-8554:中间人使用 LoadBalancer 或 ExternalIP 的缓解措施。
NodeRestriction- 将 kubelet 的权限限制为只能修改其拥有的 Pod API 资源或代表其自身的节点 API 资源。
此插件还可以防止 kubelet 使用
node-restriction.kubernetes.io/注解, 攻击者可以使用该注解来访问 kubelet 的凭证,从而影响所控制的节点上的 Pod 布局。
第三组包括默认情况下未启用,但可以考虑在某些场景下启用的插件:
AlwaysPullImages- 强制使用最新版本标记的镜像,并确保部署者有权使用该镜像。
ImagePolicyWebhook- 允许通过 Webhook 对镜像强制执行额外的控制。
接下来
- RBAC 良好实践提供有关授权的更多信息。
- 集群多租户指南提供有关多租户的配置选项建议和最佳实践。
- 博文“深入了解 NSA/CISA Kubernetes 强化指南”为强化 Kubernetes 集群提供补充资源。